9.7_RL 中的语言模型
语言模型为智能体编码有用的知识
语言模型(Language Models,LM)在操作文本方面展示了令人印象深刻的能力,例如问答或甚至逐步推理。此外,它们对大规模文本语料库的训练使它们能够编码各种知识,包括有关我们世界的物理规则的抽象知识(例如对象可做什么,旋转对象时会发生什么等)。
最近研究的一个常规问题是,这种知识是否可以使机器人等智能体在解决日常任务时受益。虽然这些工作展示了有趣的结果,但所提出的智能体缺乏任何学习方法。这种限制阻止了这些智能体适应环境(例如纠正错误的知识)或学习新技能。
LMs 和 RL
因此,语言模型可以提供关于世界的知识,而强化学习可以通过与环境的交互来调整和纠正这些知识,因此两者之间存在潜在的协同作用。从强化学习的角度来看,这尤其有趣,因为强化学习领域主要依赖于 Tabula-rasa 设置,即智能体从零开始学习所有知识,导致:
-
采样效率低下
-
从人的角度来看,出现了意想不到的行为
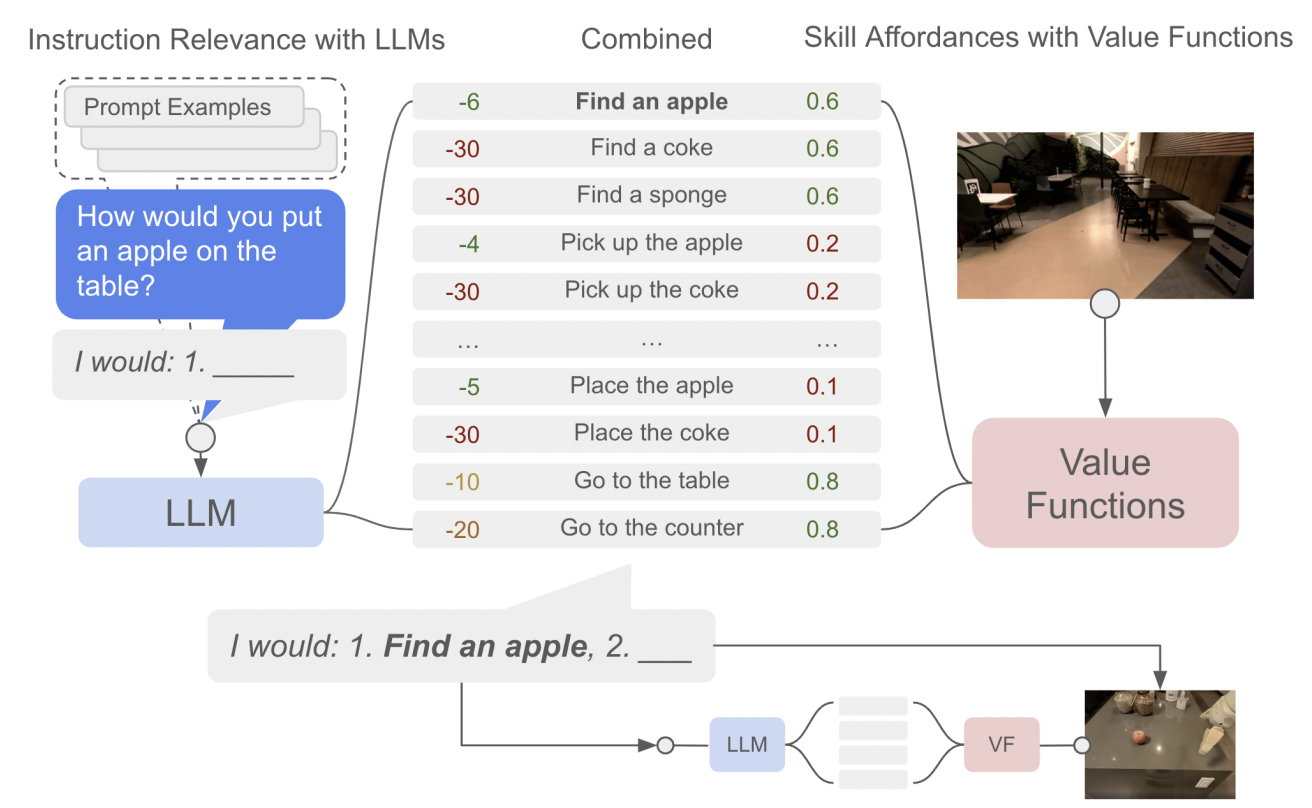
作为首次尝试,论文"Grounding Large Language Models with Online Reinforcement Learning" 解决了使用 PPO (Proximal Policy Optimization) 将 LM 适应或对齐到文本环境的问题。他们展示了,LM 中编码的知识导致了对环境的快速适应(高效采样的 RL 智能体开辟了途径),而且这样的知识使得 LM 在对齐后更好地推广到新任务。
在“Guiding Pretraining in Reinforcement Learning with Large Language Models”中研究的另一个方向是冻结语言模型(LM),但利用其知识来指导强化学习智能体的探索。这种方法使得强化学习智能体能够朝着对人类有意义和合理有用的行为方向进行引导,而无需在训练过程中需要人类参与。
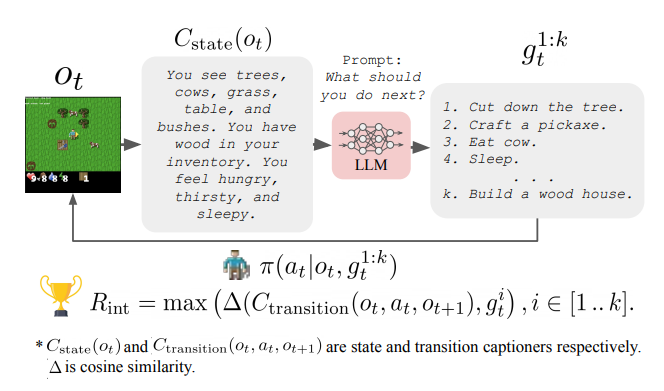
这些工作还存在一些限制,使得它们仍然非常初步,例如需要将智能体的观测转换为文本,然后将其输入到语言模型中,以及与非常大的语言模型进行交互的计算成本。
补充阅读
如需了解更多信息,推荐查阅以下资源:
作者
本节由 Clément Romac 撰写