9.3_离线与在线强化学习
深度强化学习是一个构建决策智能体的框架。这些智能体旨在通过与环境的互动和接收奖励作为唯一的反馈,通过试错来学习最佳行为(策略)。
智能体的目标是最大化其累积奖励,即回报。因为强化学习基于奖励假设:所有目标都可以描述为期望累积奖励的最大化。
深度强化学习智能体使用经验的批次进行学习。问题是,它们如何收集经验?
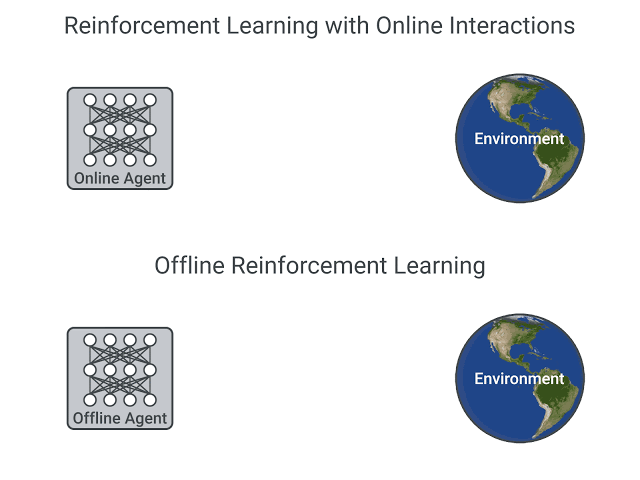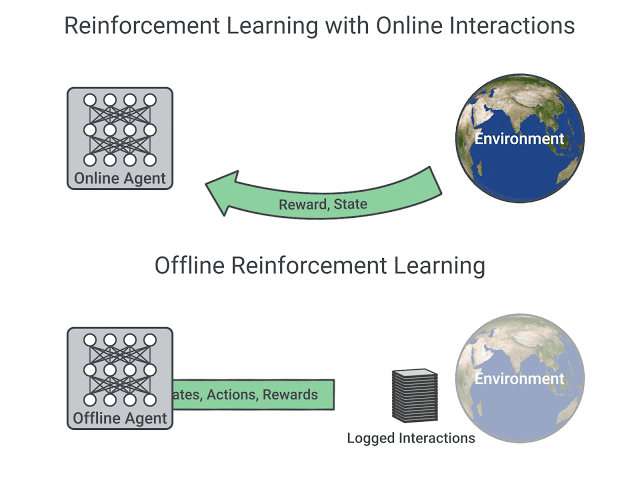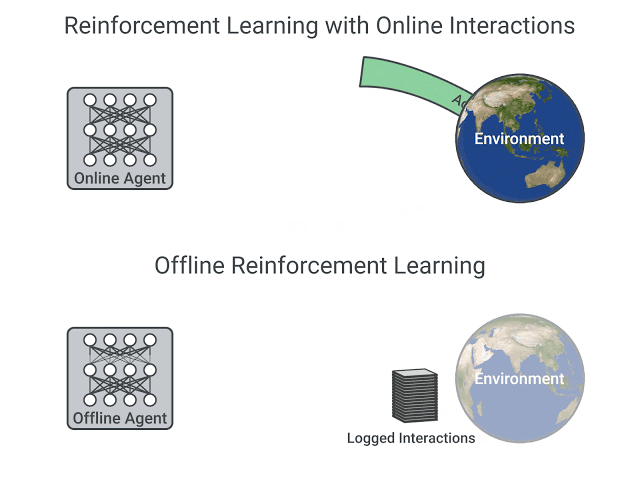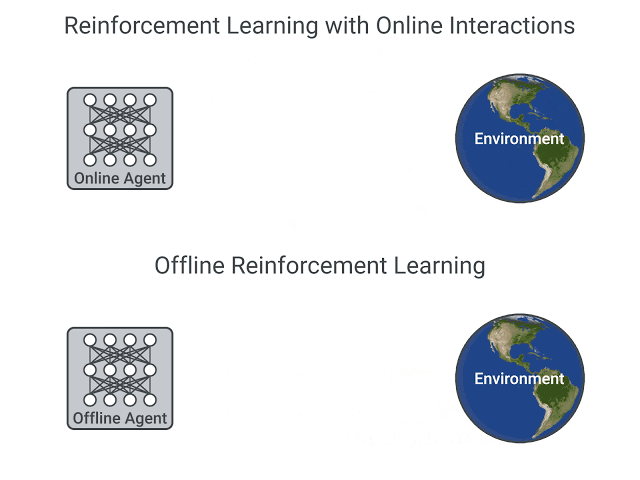
- 在在线强化学习中,也就是我们在本课程中学到的内容,智能体直接收集数据:通过与环境的交互,它收集一批经验数据。然后,它立即(或通过某个重放缓冲区)利用这些经验数据进行学习(更新策略)。
但这意味着你要么直接在真实世界中训练智能体,要么拥有一个模拟器。如果没有模拟器,你需要构建一个,这可能非常复杂(如何在环境中反映现实世界的复杂性?)、昂贵且不安全(如果模拟器存在缺陷,可能提供竞争优势,智能体将利用这些缺陷)。
- 另一方面,在离线强化学习中,智能体只使用从其他智能体或人类演示中收集的数据。它不与环境进行交互。
该过程如下:
- 使用一个或多个策略和/或人类交互来创建数据集。
- 在此数据集上运行离线强化学习以学习一种策略。
这种方法有一个缺点:反事实查询问题。如果我们的智能体决定做某件我们没有数据的事情,我们该怎么办?例如,在交叉口右转,但我们没有这样的轨迹。
关于这个问题存在一些解决方案,如果想要了解更多关于离线强化学习的内容,可以观看这个视频。
补充阅读
如需了解更多信息,我们建议你查阅以下资源:
作者
本节内容由 Thomas Simonini 撰写。