7.3_设计多智能体系统
在本节中,你将观看由 Brian Douglas 制作的关于多智能体的优秀介绍视频。你可以在这里找到视频。
在这个视频中,Brian 讲解了如何设计多智能体系统。他特别以一个吸尘器多智能体场景为例,探讨了它们如何相互合作。
我们有两种设计多智能体强化学习系统(MARL)的解决方案。
分布式系统
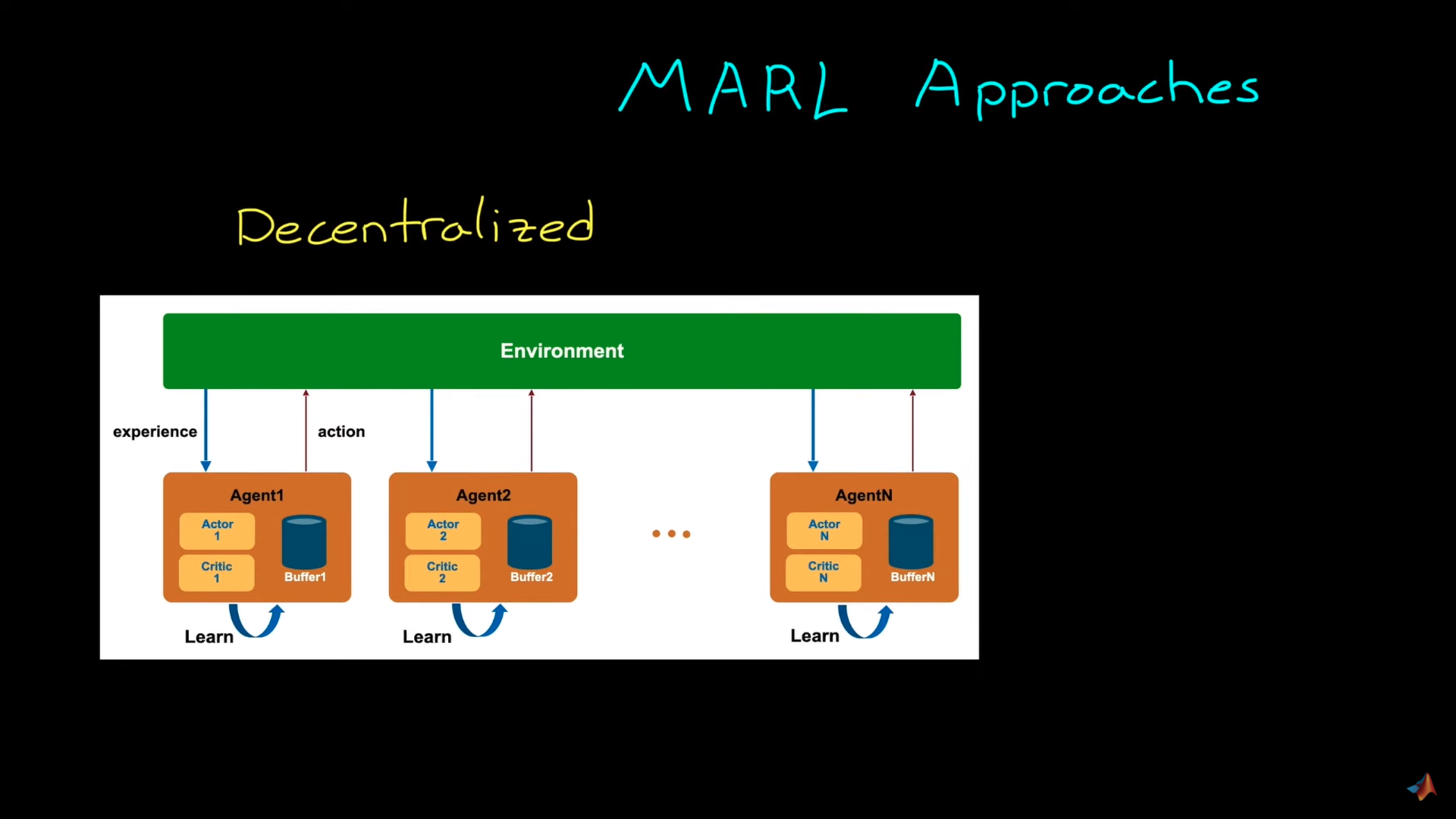
在分布式学习中,每个智能体都独立地进行训练,不受其他智能体的影响。在给定的示例中,每个吸尘器学习尽可能清洁尽可能多的地方,而不关心其他吸尘器(智能体)的行为。
好处在于,由于智能体之间不共享信息,这些吸尘器可以像训练单个智能体一样进行设计和训练。
这里的思想是,我们的训练智能体将其他智能体视为环境动力学的一部分,而不是智能体。
然而,这种技术的一个重大缺点是它将使环境非稳态,因为随着其他智能体也在环境中进行交互,底层的马尔可夫决策过程会随时间改变。这对于许多强化学习算法是有问题的,因为它们无法在非稳态环境中达到全局最优。
集中式方法
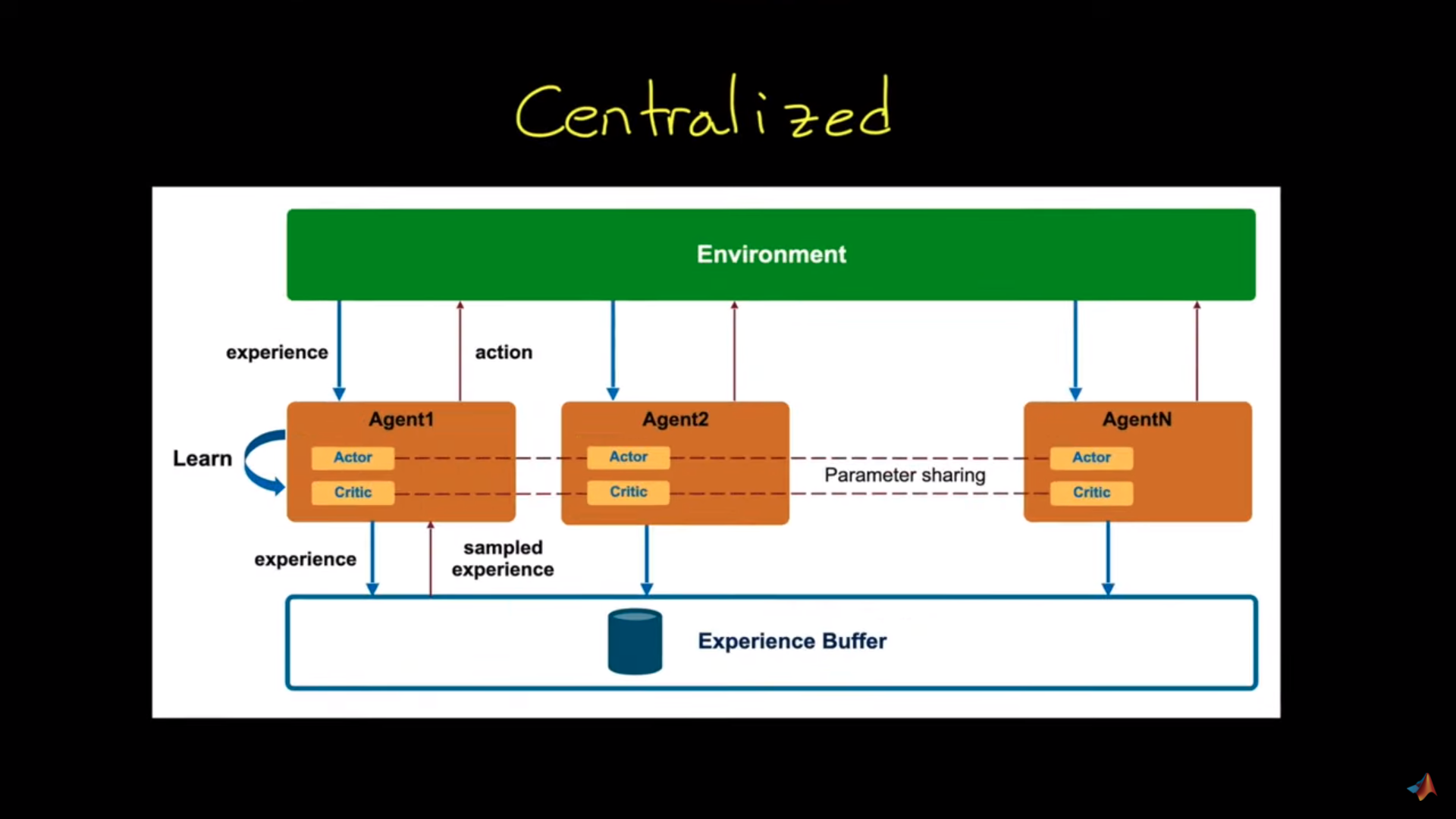
在这种架构中,我们有一个高级过程来收集智能体的经验,即经验缓冲区。我们将利用这些经验来学习一个共同的策略。
例如,在吸尘器系统中,观察将包括:
- 吸尘器的覆盖地图。
- 所有吸尘器的位置。
我们利用这些共同的经验来训练一个策略,以整体上以最有益的方式移动所有三个机器人。因此,每个机器人都从共同的经验中学习。而且,由于所有智能体被视为一个更大的整体,它们知道其他智能体策略的变化(因为它与它们的策略相同),所以我们拥有一个稳态的环境。
如果我们回顾一下:
-
在分布式方法中,我们将所有智能体独立地对待,不考虑其他智能体的存在。
- 在这种情况下,所有智能体将其他智能体视为环境的一部分。
- 这是一个非稳态环境条件,所以无法保证收敛。
-
在集中式方法中:
- 从所有智能体中学习一个单一策略。
- 输入为环境的当前状态和策略输出的联合动作。
- 奖励是全局的。