7.2_多智能体强化学习 (MARL) 介绍
从单智能体到多智能体
在第一个单元中,我们学习了如何在单智能体系统中训练智能体。在这种情况下,我们的智能体是独自存在于环境中的,它不与其他智能体进行合作或协作。
当进行多智能体强化学习(MARL)时,我们处于这样一种情况:有多个智能体共享并相互作用于一个共同的环境。
例如,可以想象一个仓库,其中多个机器人需要在其中导航以装载和卸载包裹。

或者是一条道路上有多辆自动驾驶车辆。
在这些例子中,我们有多个智能体与环境和其他智能体进行交互。这意味着我们需要定义一个多智能体系统。但首先,让我们了解不同类型的多智能体环境。
不同类型的多智能体环境
在多智能体系统中,智能体与其他智能体进行交互,我们可以有不同类型的环境:
- 合作环境:在这种环境中,你的智能体需要最大化共同的利益。
例如,在一个仓库中,机器人必须协作以尽可能高效地装卸货物(尽快)。
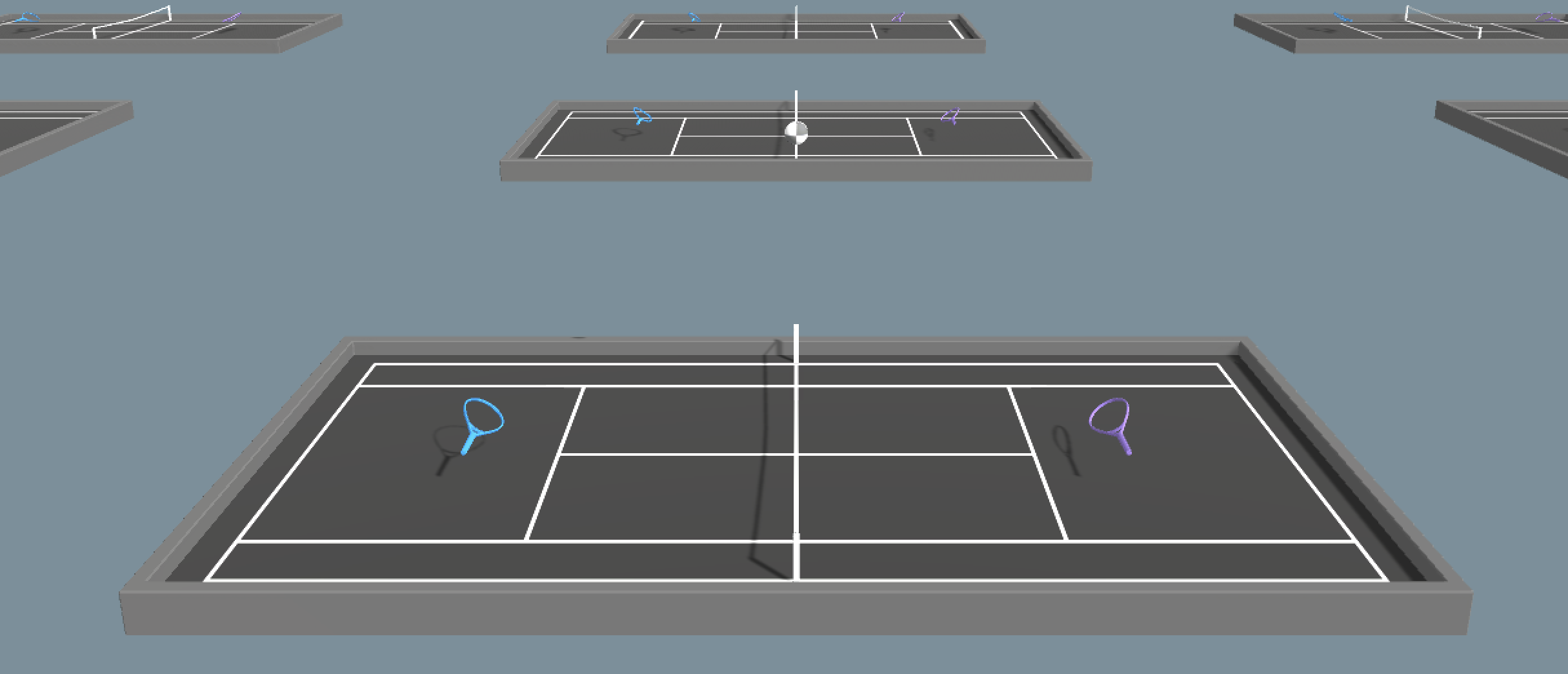
- 竞争/对抗环境:在这种情况下,你的智能体希望通过最小化对手的利益来最大化自身的利益。
例如,在一场网球比赛中,每个智能体都想击败对手。
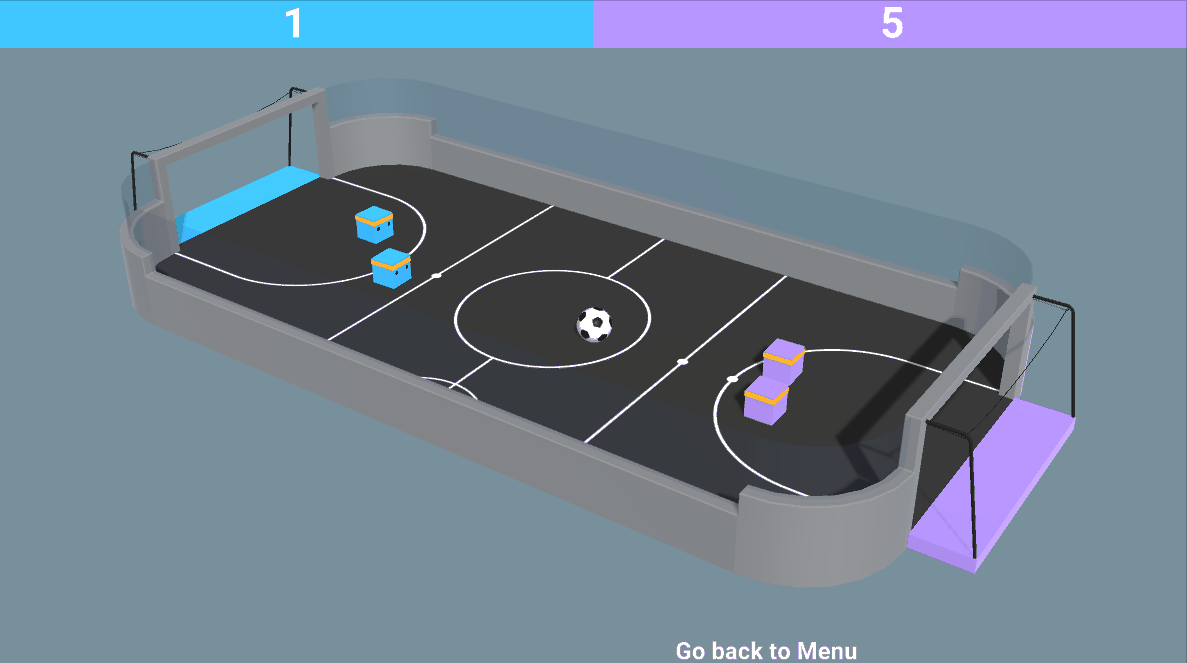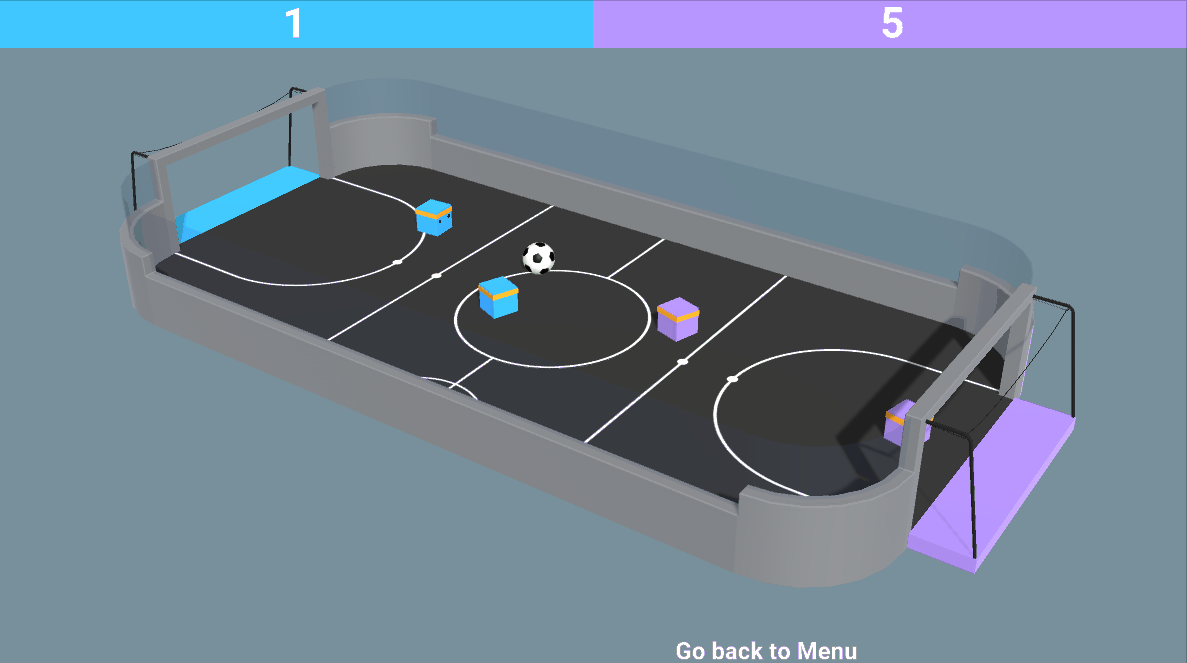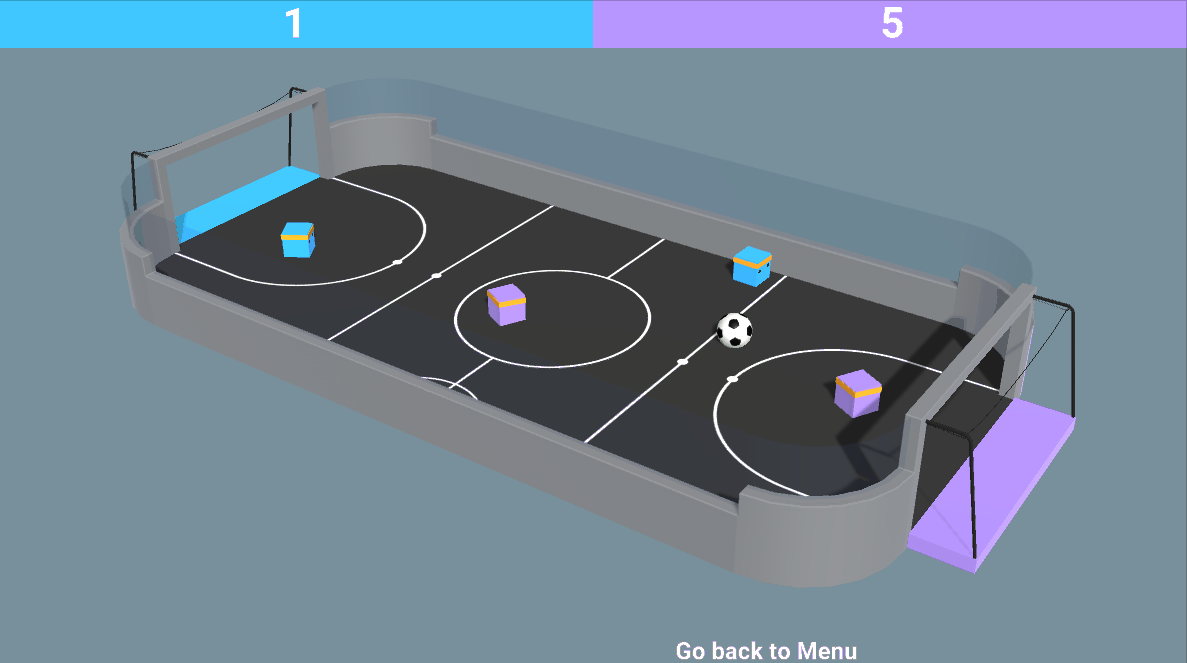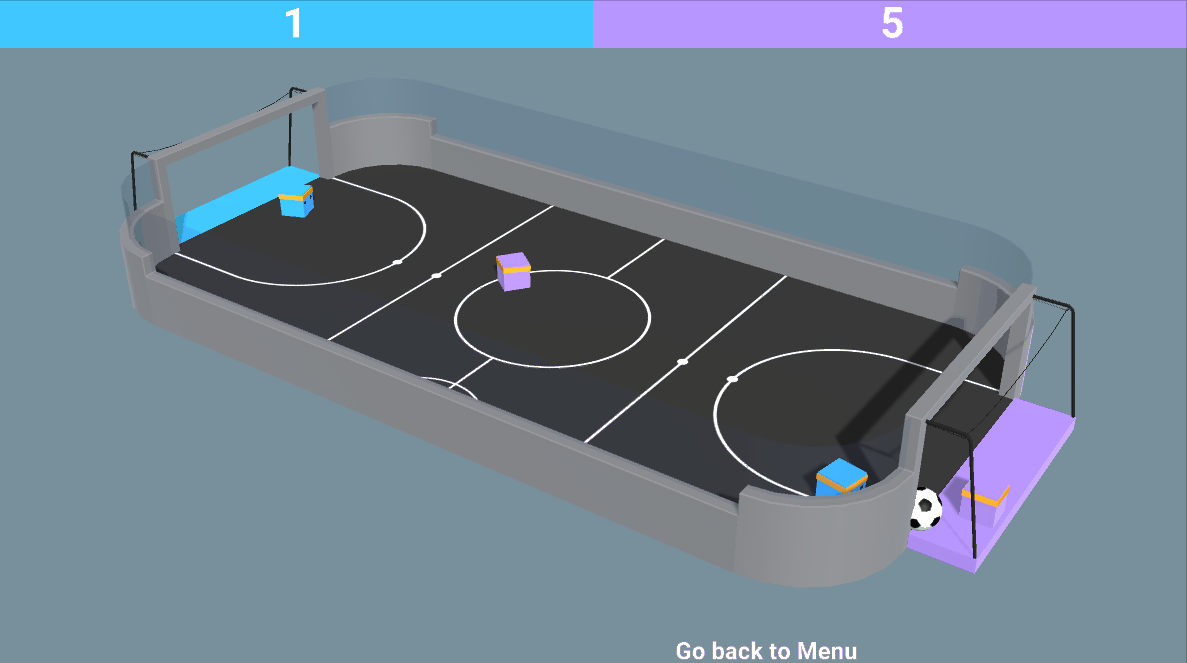
- 既对抗又合作的混合环境:就像在我们的 SoccerTwos 环境中一样,两个智能体是同一个团队的一部分(蓝色或紫色):它们需要相互合作并击败对手团队。
那么现在我们可能会想知道:我们应该如何设计这些多智能体系统呢?换句话说,我们如何在多智能体环境中训练智能体呢?