5.2_Unity ML_Agents怎样工作
在训练我们的智能体前 ,我们需要理解 什么是 ML-Agents 并且他是怎么工作的。
什么是 Unity ML-Agents?
Unity ML-Agents 是游戏引擎 Unity 的一个工具包,这个工具包允许我们使用 Unity 创建环境或者用预置环境来训练我们的智能体。
ML-Agents 是 Unity Technologies, Unity 的开发者们, 研发的。该引擎是 Firewatch, Cuphead, 和 Cities: Skylines 等游戏创作者使用的最著名的游戏引擎之一。

六个组成部分
在 Unity ML-Agents 中, 你有六个非常重要的部分:

- 第一个部分就是 Learning Environment, 这个部分包含了** Unity 场景 (环境) 和环境元素** (游戏角色)。
- 第二个部分是 Python Low-level API, 这个部分包含了低等级 Python 接口,其作用是用来交互和操作环境的。这是我们用来开始训练的 API。
- 然后是 External Communicator ,这部分连接了学习环境(用 C# 编写的) 和低等级 Python API。
- Python trainers: 使用 PyTorch 制作的强化算法(PPO、SAC……)。
- Gym wrapper: 将 RL 环境封装在 gym wrapper 中。
- PettingZoo wrapper: PettingZoo 是多智能体的 gym wrapper。
学习组件内部
在学习组件中,我们有两个重要元素:
- 首先是智能体组件,是场景的演员。我们将通过优化其策略(这将告诉我们在每个状态下采取什么动作)来训练训练智能体。该策略称为 Brain。
- 最后,还有 学院。该组件协调智能体及其决策过程。将这个学院想象成处理 Python API 请求的老师。
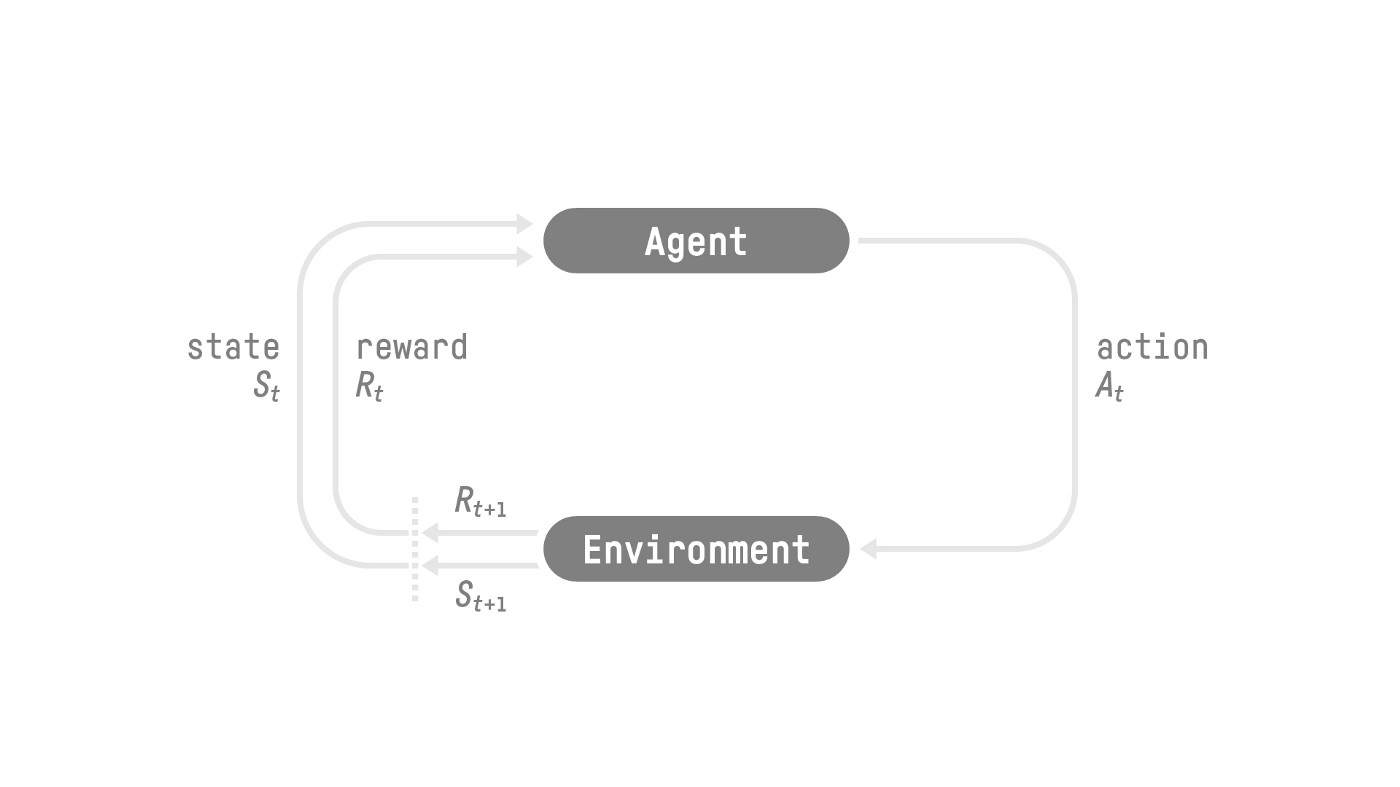
为了更好地理解它的作用,让我们记住 RL 过程。这可以建模为一个循环,其工作方式如下:
现在,让我们想象一个智能体学习玩平台游戏。RL 过程如下所示:
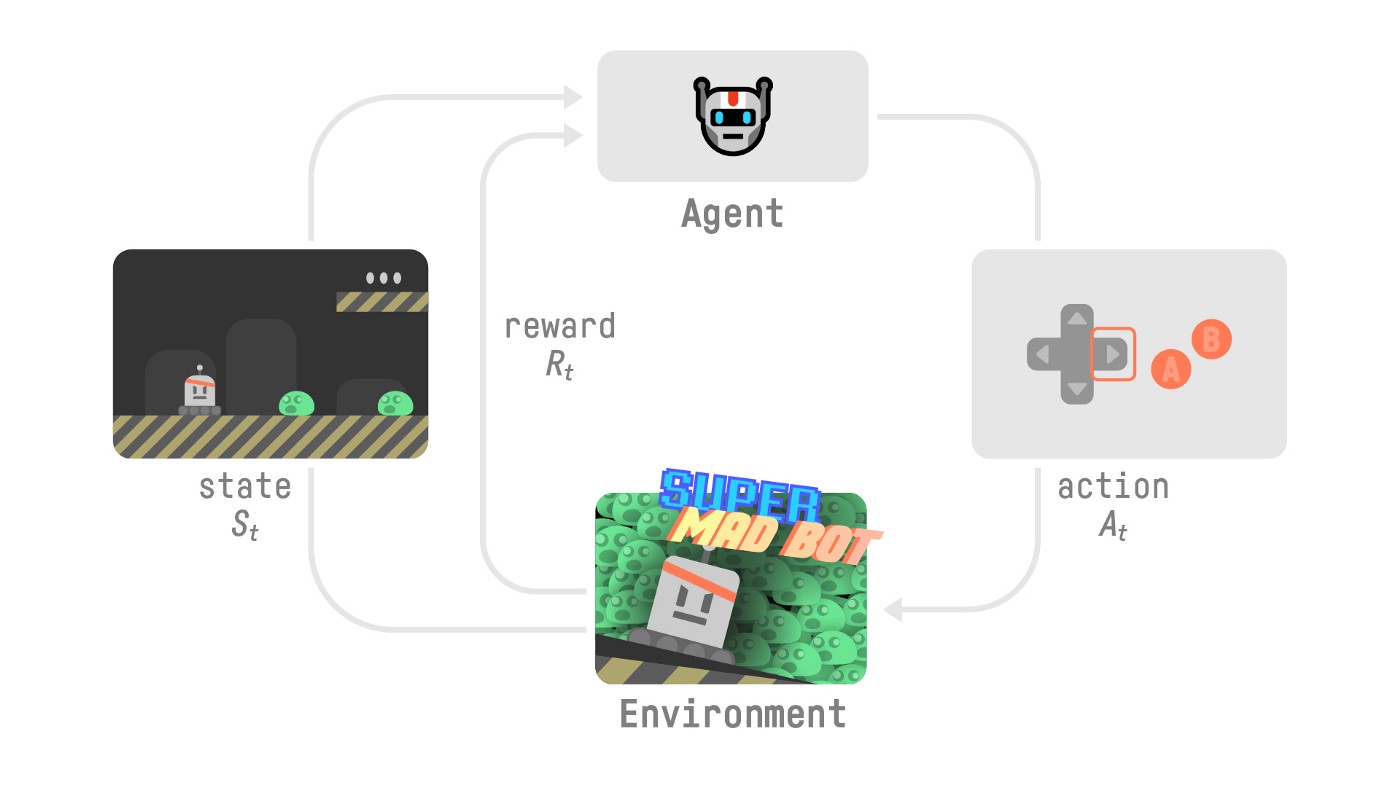
- 我们的智能体从环境接收状态 \(S_0\) —这是我们接收我们游戏(环境)的第一帧。
- 基于那个状态 \(S_0\),智能体采取动作 \(A_0\)** —我们的智能体将向右移动。
- 环境会变化进入新状态 \(S_1\) — 新一帧。
- 环境会给智能体一些奖励 \(R_1\)— 我们如果没有死*(正向奖励 +1)*。
这个 RL 循环输出一系列 状态、动作、奖励和下一个状态。智能体的目标是最大化预期的累积奖励。
学院将向我们的智能体发送命令并确保智能体的同步:
- 收集观察
- 使用你的策略选择你的动作
- 采取动作
- 如果你达到最大步数或完成,请重置。

既然我们了解了 ML-Agents 的工作原理,我们就可以训练我们的智能体了。