4.2_什么是基于策略的方法?
强化学习的主要目标是找到最优策略 \(\pi^{*}\) 可以最大化累积奖励期望。 因为强化学习是基于奖励假设:所有目标可以被描述为累计奖励期望的最大化。
举个例子,在足球比赛中(你在第二单元中训练的智能体),你的目标是赢得比赛。我们在强化学习中可以把这个目标描述为最大化进球数(当球越过球门线时)进入对手的足球门,并最小化进入你自己的足球门的进球数。

基于价值,基于策略,和演员-评论员方法
我们在第一单元的学习中,我们有两个方法去寻找(大部分时间是近似)最优策略 \(\pi^{*}\)。
-
在基于价值的方法中,我们学习了价值函数。
- 核心思想是一个最优价值函数导向最优策略 \(\pi^{*}\)。
- 我们的目标是最小化预测和目标价值之间的损失来估计真正的动作价值函数。
- 我们有一个策略,但这是隐式的,因为它是直接从价值函数生成的。例如,在 Q-learning 中,我们定义了(epsilon-)贪心策略。
-
在另一方面,在基于策略方法中,我们直接近似 \(\pi^{*}\) 而不用学习价值函数。
- 核心思想是参数化策略。举个例子,用神经网络 \(\pi_\theta\),这个策略将输出动作的概率分布(随机策略)。
-

- 我们的目标是用梯度上升最大化参数化策略的性能
- 为此,我们控制参数 (\theta\) 来影响一个状态上动作的分布。
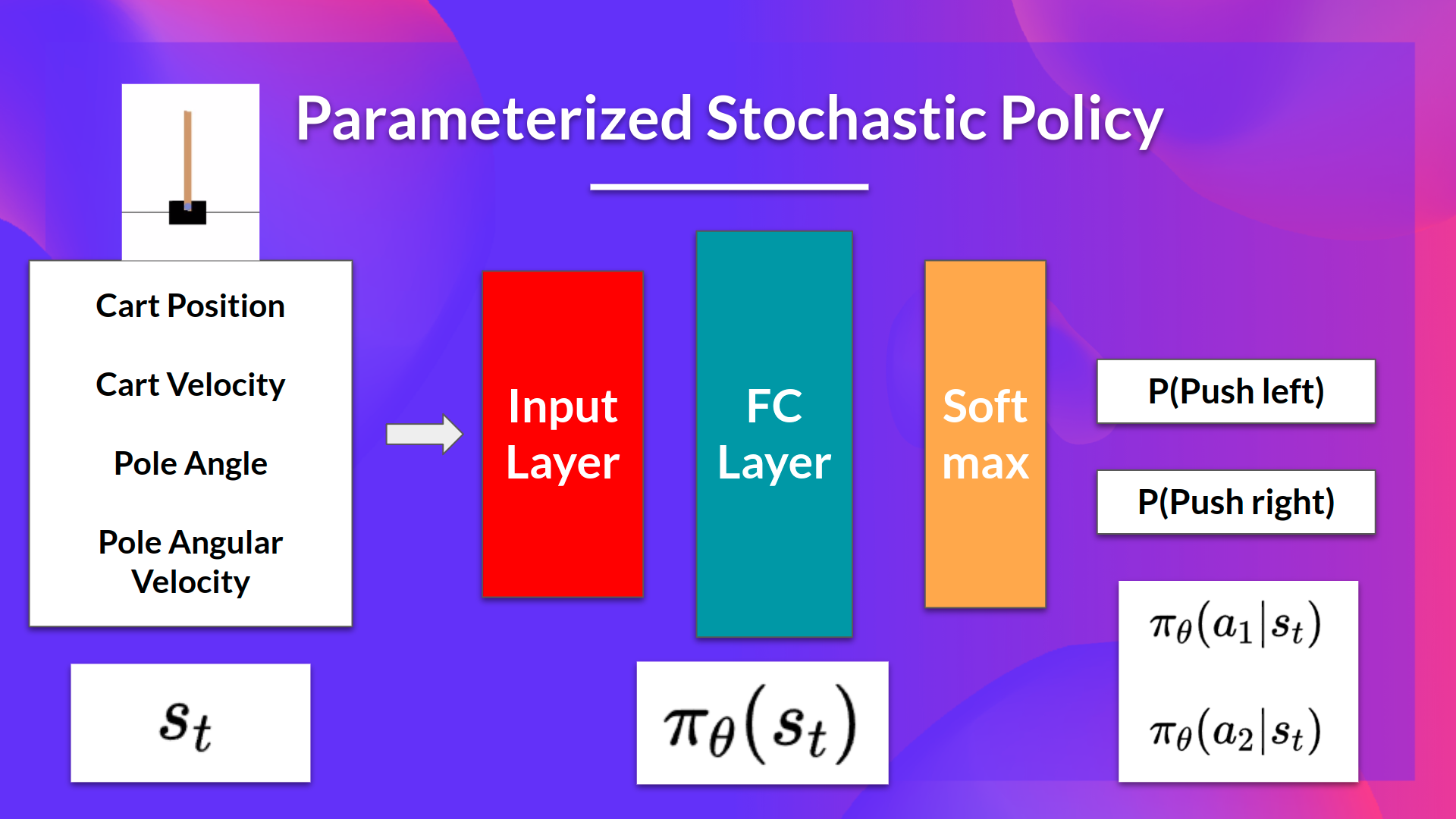
- 下次我们会学习演员-评论员方法,这是基于价值和基于策略的方法的结合。
所以,多亏了基于策略的方法,我们可以直接最优化我们的策略 \(\pi_\theta\) 来输出动作的概率分布 \(\pi_\theta(a|s)\),从而得到最佳累积回报。为了达到这个目的,我们定义了目标函数 \(J(\theta)\),其代表期望累积奖励,并且我们想要找到可以最大化目标函数的 \(\theta\)。
基于策略和策略梯度方法的不同
策略梯度方法,我们将要在本单元学习的内容,是一种基于策略方法的子类。在基于策略的方法中,优化大部分时间都是同策略的,因为对于每次更新,我们只使用由我们最近版本的 \(\pi_\theta\) 收集的数据(轨迹)。
两种方法的不同之处在于我们怎么优化参数 \(\theta\):
- 在基于策略的方法中,我们直接从最优策略搜索。我们可以使用技术(如爬山法、模拟退火或进化策略)通过最大化目标函数的局部近似来间接地优化参数 \(\theta\) 。
- 在策略梯度方法中,因为是基于策略方法的子类,我们直接搜索最优策略。但是我们通过在目标函数 \(J(\theta)\) 上执行梯度上升直接优化参数 \(\theta\) 。
在深入了解策略梯度方法如何工作(目标函数、策略梯度定理、梯度上升等)之前,让我们先研究一下基于策略的方法的优缺点。