3.3_深度 Q 网络 (DQN)
这是我们深度 Q-learning 网络的结构:
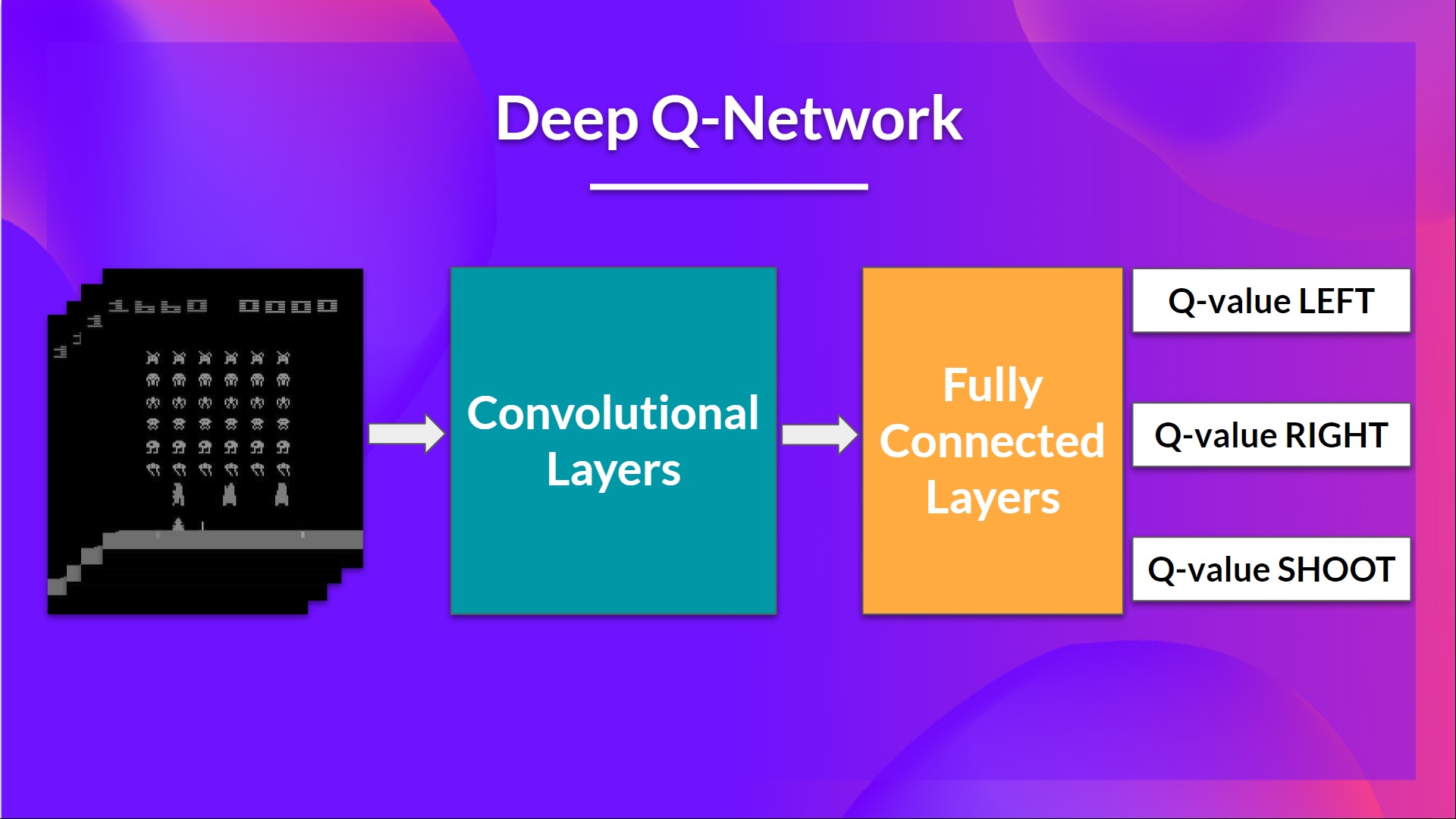
作为输入,我们的状态采用 4 帧的堆经过网络,并且输出一个该状态下每个可能动作的 Q 值向量。然后像 Q-learning 一样,我们仅仅需要使用
当神经网络开始初始化, Q 值的估计很糟糕。但是随着训练进行,深度 Q 网络会将情况与合适的动作关联起来,并学习如何玩好游戏。
预处理输入和时序限制
我们需要预处理输入。因为我们想要减少状态的复杂度,从而减少训练的计算时间,所以这是一个重要的步骤。
为了达到这个目标,我们减少状态空间到 84x84 并且进行灰度化。之所以这样做,是因为颜色在雅达利环境中没有增加重要的信息。这是一个重要的进步,因为我们把 3 通道(RGB)降低到 1 通道
我们也可以某些游戏中屏幕的一部分,如果它不包含重要信息。然后我们把 4 个帧堆在一起。
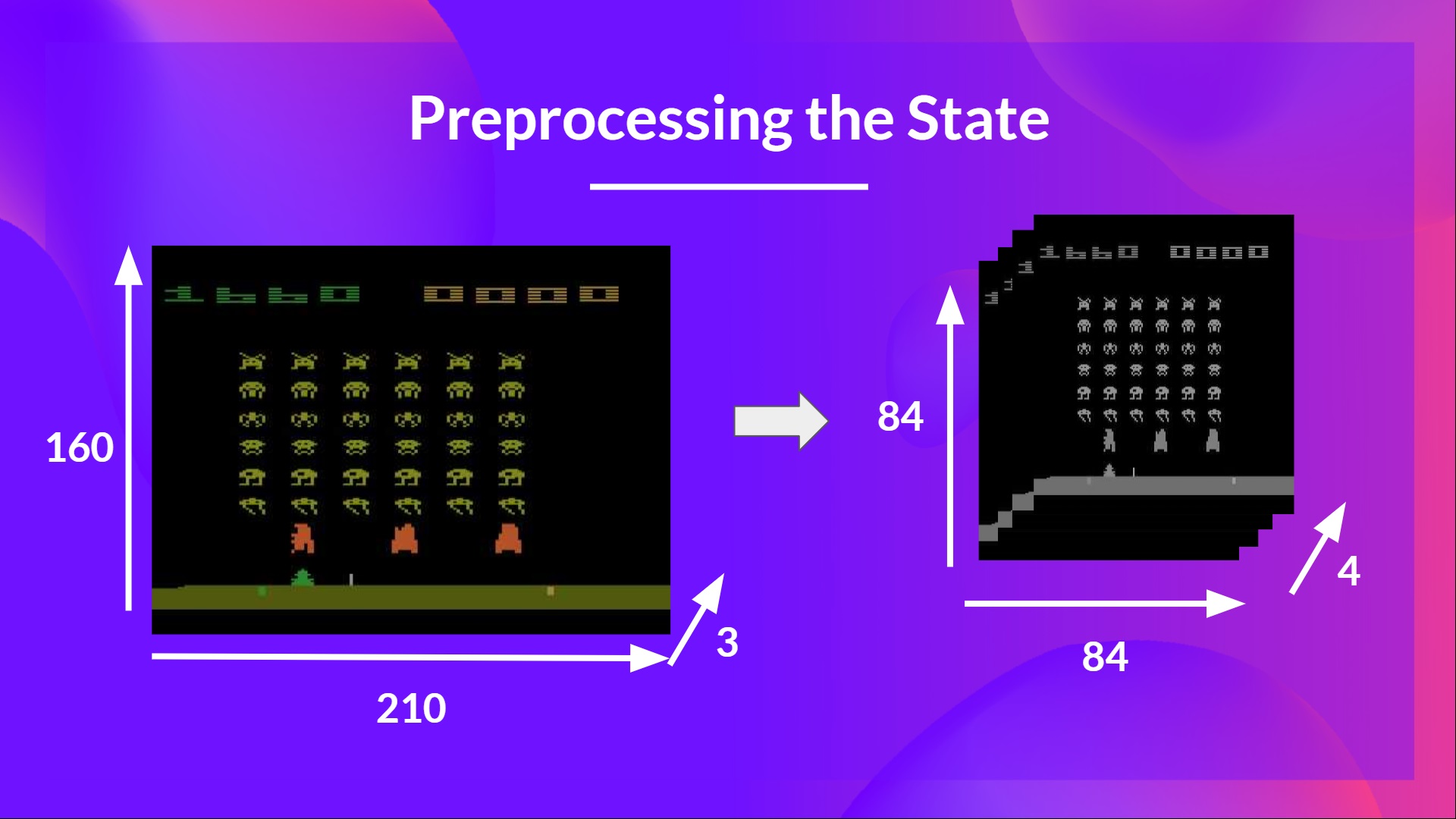
为啥要堆在一起呢?
因为这帮助我们处理一些时序限制问题。以 Pong 这个游戏举例,当你看到如下帧:

你能告诉我那个球将要去哪里吗?
不,你不能。因为一个帧没有足够的运动信息。但是如果我增加多三张呢?这里你可以看到球要向右方向运动
 这就是为什么去抓取时序信息并且堆叠 4 帧在一起。
这就是为什么去抓取时序信息并且堆叠 4 帧在一起。
后面,堆叠的帧经过三层卷积层处理,这些层允许我们捕获和利用图片中的空间关系。同样因为帧是堆叠在一起的,你也可以从中利用一些时序属性。
如果你不知道啥是卷积层,别担心。你可以查看Udacity 的深度学习课程第四课
最后,我们有几个全连接层,其在该状态下为每个可能的动作输出一个 Q 值。
因此,我们了解了深度 Q-learning 使用神经网络来近似给定一个状态,该状态下每个可能动作的不同 q 值。
下面让我们学习深度 Q-learning 算法。