3.2_从 Q-learning到深度 Q-learning
我们已知 Q-learning 是我们用来训练我们的 Q 函数(一个决定在特定状态并在该状态采取特定动作的动作价值函数)的一种算法。
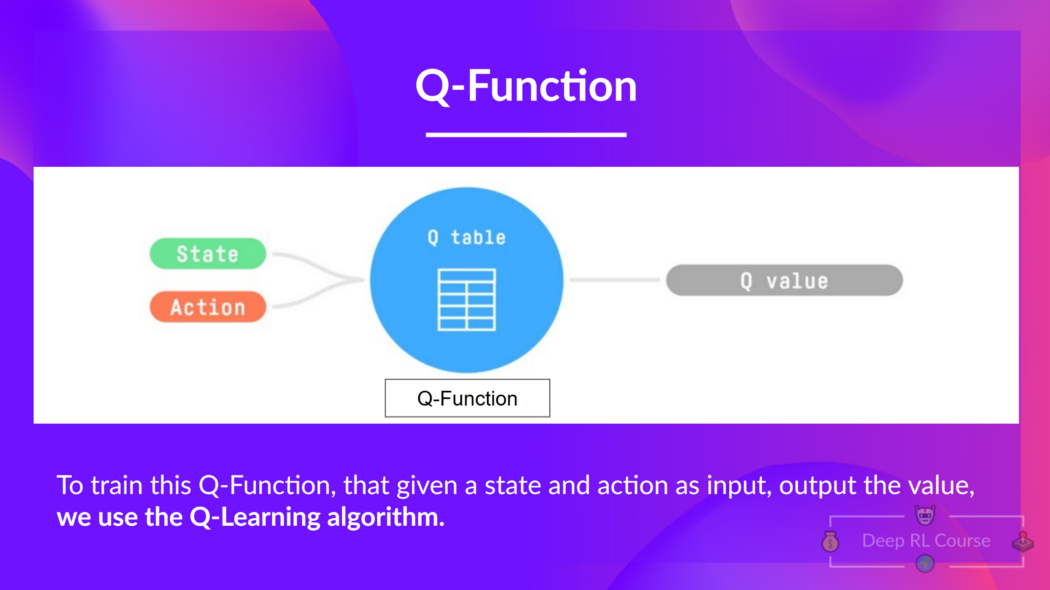
Q 代表那个状态下的动作的质量。
在内部,我们的 Q 函数有一个 Q 表格 (一张每个格子对应状态-动作对的值的表)。把这个 Q 表格当作 Q 函数的记忆或者备忘录。
这里的问题是 Q-learning 是表格型方法。如果状态和动作动作不够小,无法用数组和表格有效地表示。同样,它也不可扩展。Q-learning 在状态空间较小的环境效果很好,比如:
- FrozenLake, 我们有 16 个状态.
- Taxi-v3, 我们有 500 个状态.
但是想一下我们今天要干啥:我们将要用帧作为输入来训练一个智能体学习太空侵略者这种更复杂的游戏。
Nikita Melkozerov 曾说, 雅达利环境 有一个大小为 (210, 160, 3)* 的观测空间, 包含值的范围从 0 到 255,也就是大致给了我们 \(256^{210 \times 160 \times 3} = 256^{100800}\)可能的观测(作为对比,在可观测宇宙中我们有\(10^{80}\) 个原子).
- 雅达利中的一帧由一张 210x160 像素的图片组成。给定的图片是彩色的,有 3 个通道。这也是为什么形状大小是 (210, 160, 3)。对于每一个像素,取值在0 到 255 之间。
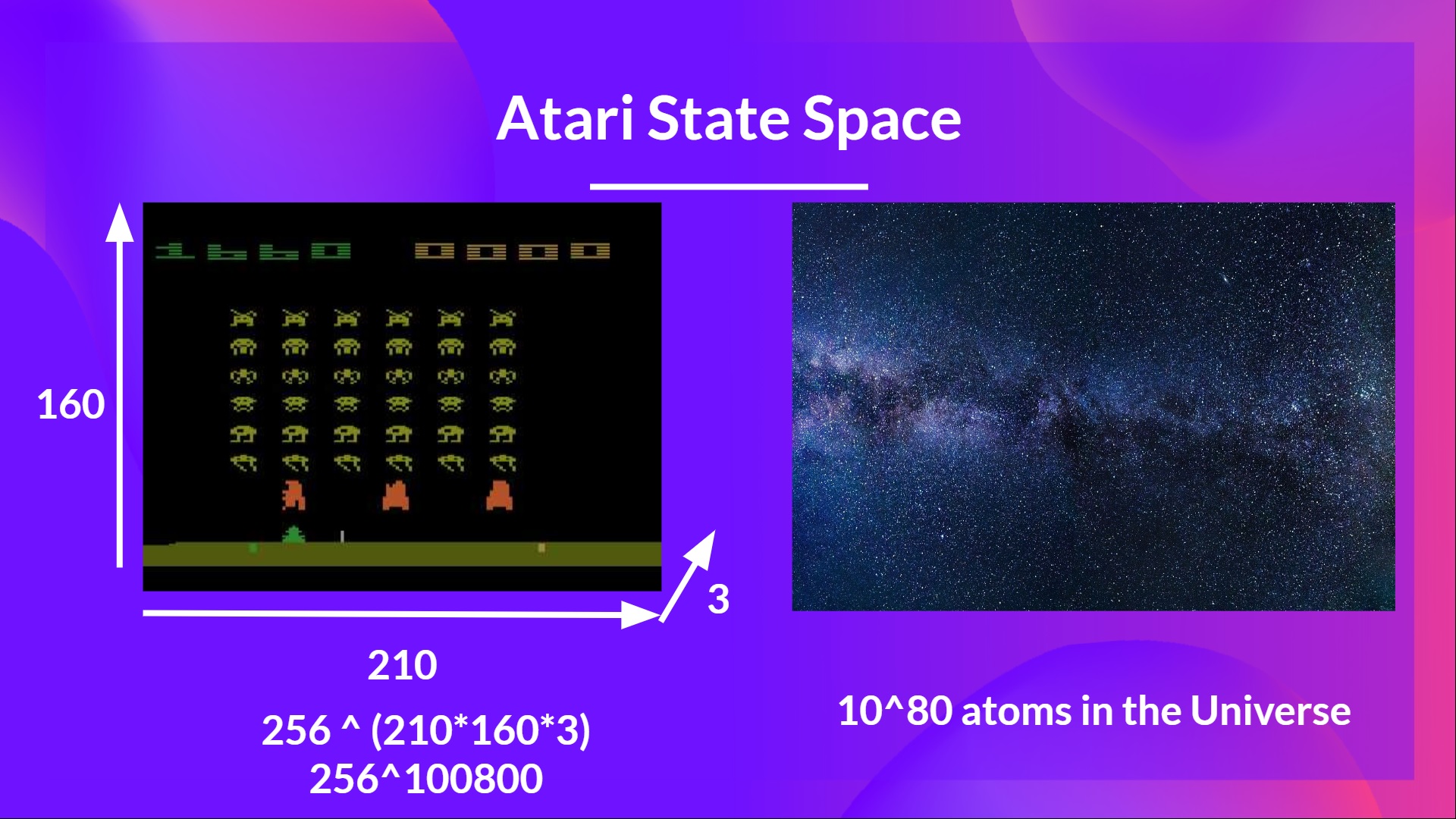
因此,状态空间是巨大的。所以在这种环境下创建和更新 Q 表格会失效。针对这种情况,最好的方法是用参数化 Q 函数 \(Q_{\theta}(s,a)\) 去估计 Q 值而不是用 Q 表格。
神经网络会进行估计,对于给定状态下每个可能的动作给出不同的 Q 值。这就是深度 Q-learning 干的事情。
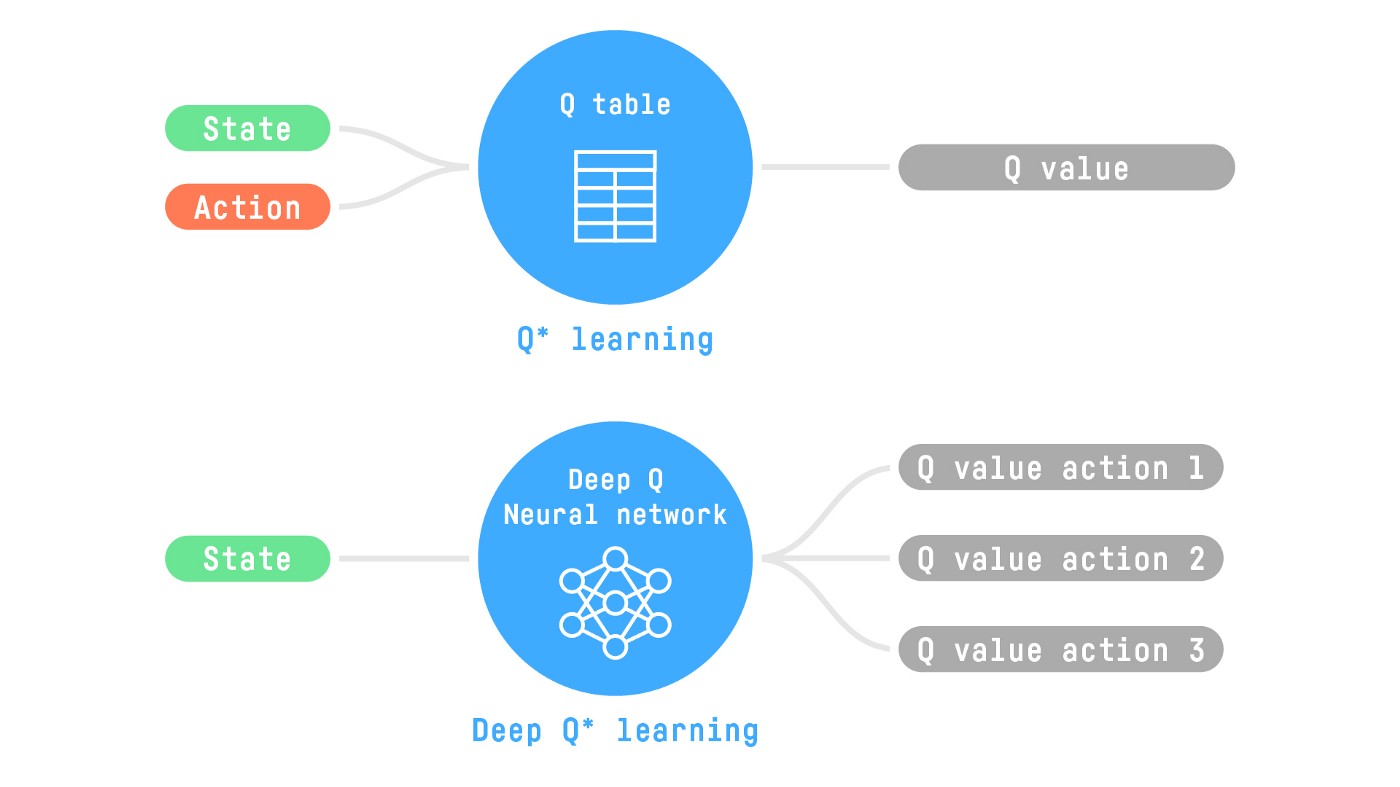
现在我们理解了深度 Q-learning ,下面让我们深入了解深度 Q 网络。