2.7_Q-learning 算法实例
为了更好的理解 Q-learning 算法,我们举一个简单的例子:

- 假如你是一个处在小迷宫中的小老鼠,并总是从相同的起点开始出发。
- 你的目标是吃掉右下角的大块奶酪,并且避免吃到毒药。毕竟相比于小块奶酪,谁会不喜欢大块奶酪呢?
- 在每次探索中,如果吃到毒药、吃掉大块奶酪或行动超过五步,则该次探索结束。
- 学习率为 0.1。
- Gamma(折扣率)为 0.99。

奖励函数如下:
- +0: 去一个没有奶酪的状态。
- +1: 去一个有小奶酪的状态。
- +10: 去一个有一大堆奶酪的状态。
- -10: 去一个有毒药的状态,从而死亡。
- +0 如果我们花了超过五步。

我们将使用 Q-learning 算法训练智能体,使其能够具有最优策略(即能够依次做出向右、向右、向下动作的策略)。
第一步: 初始化 Q 表格

目前,** Q 表格是没用的**;所以我们需要使用 Q-learning 算法来训练 Q 函数。
我们进行 2 个训练时间步的训练:
训练时间步 1:
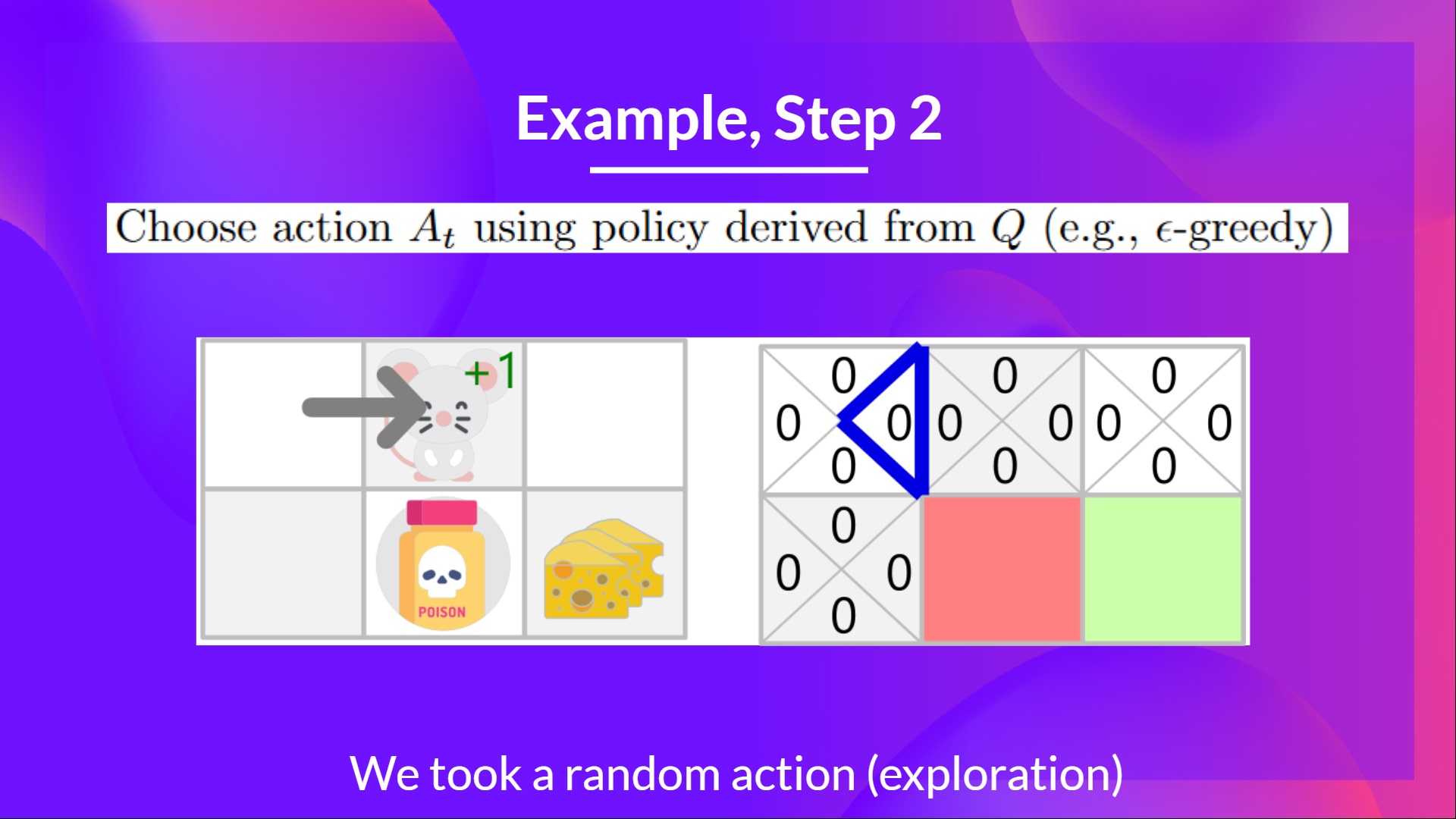
第二步:使用 epsilon 贪心策略选择动作
因为epsilon很大,等于1.0,所以你随机选择了一个向右的行动。
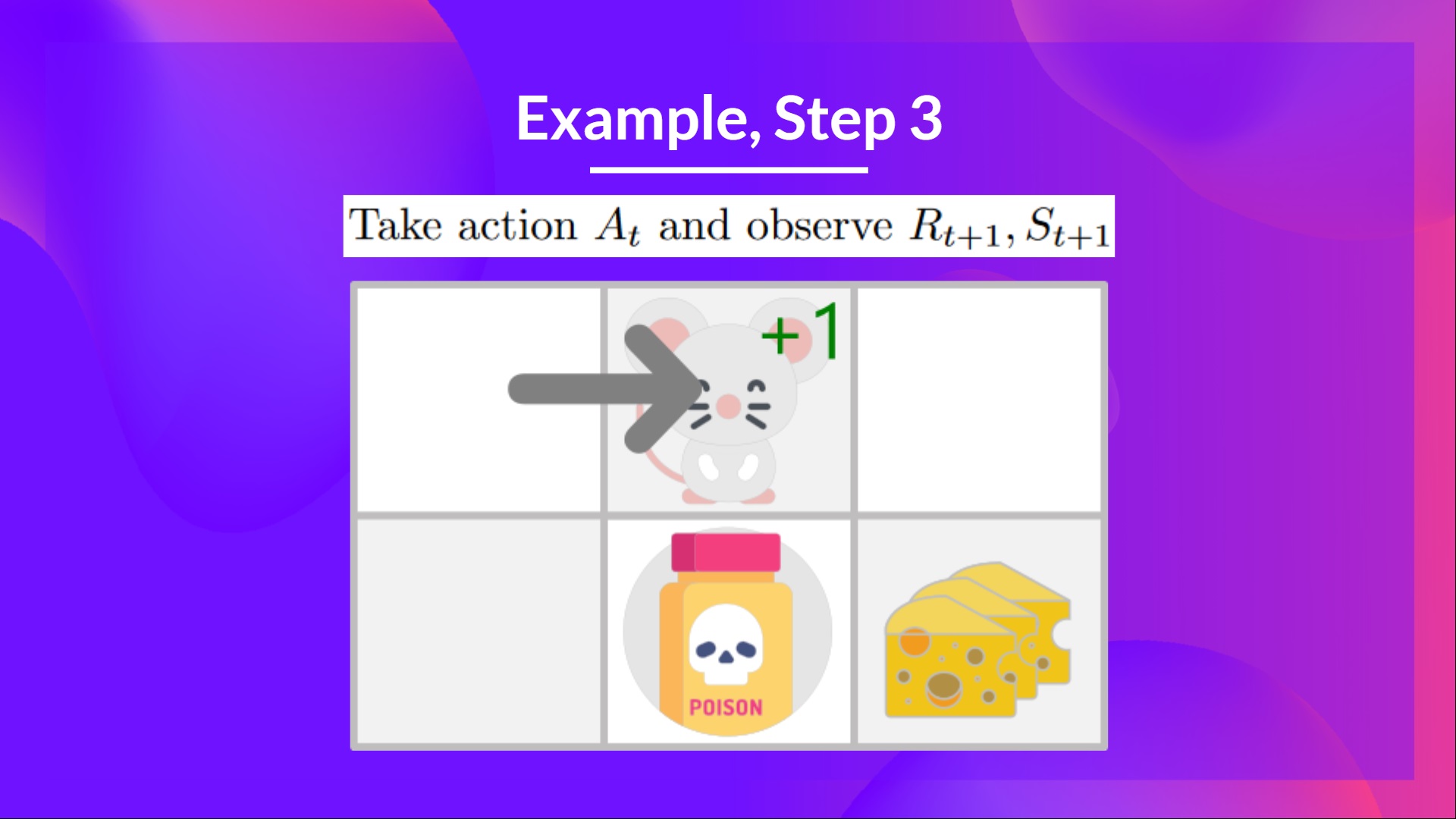
第三步:执行动作At,得到奖励Rt+1和新的状态St+1
向右走后,你得到了一块小奶酪,所以(R_{t+1} = 1),并且你进入了一个新的状态。
第四步:更新 Q(St, At)
现在我们可以使用公式更新 Q(St,At)。


第二次训练(不需要再对 Q 表格进行初始化):
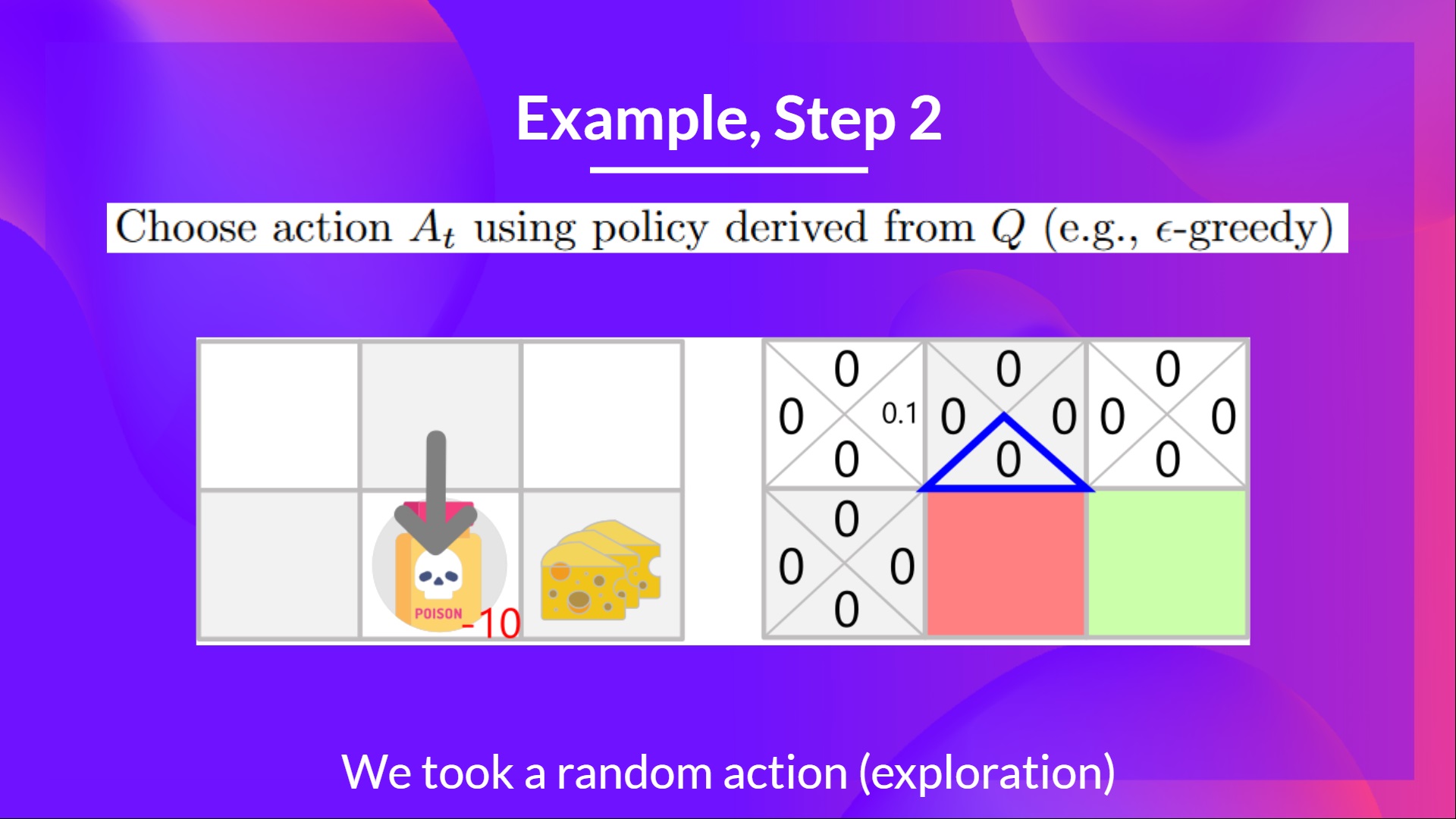
第二步:使用 epsilon 贪心策略选择动作
由于 epsilon 还是很大,为 0.99,所以你再次随机选择一个行动(随着训练的进行,我们希望越来越少探索,所以我们把 epsilon 逐渐减小)。
你选择了一个向下的动作。这是一个糟糕的行动,因为它让小老鼠吃到了毒药。
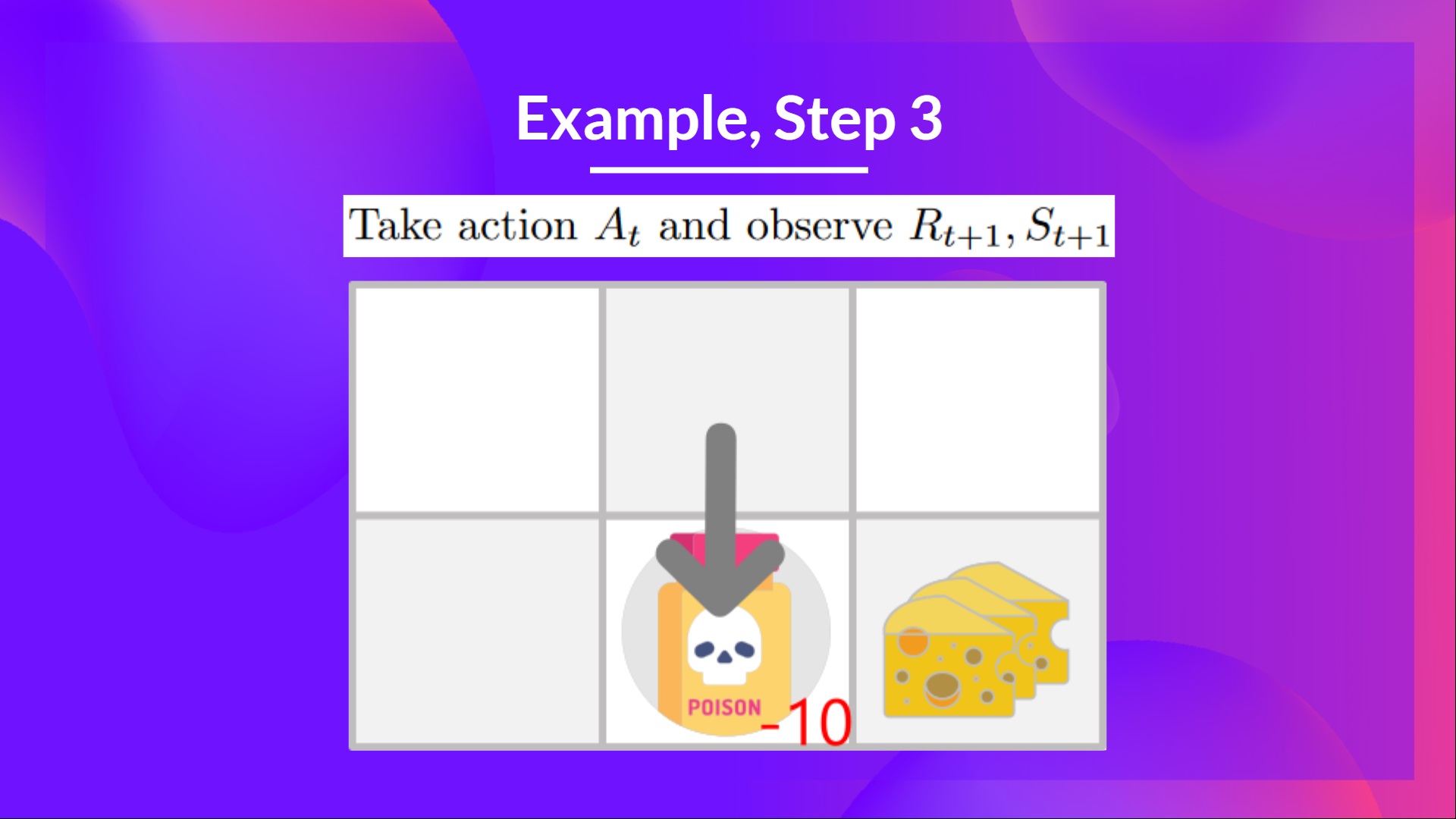
第三步:执行动作 At,得到奖励 Rt+1 和新的状态 St+1
因为不小心吃到了毒药,所以小老鼠不幸死亡,得到的奖励 Rt+1 = -10,。
第四步:更新 Q(St, At)

因为小老鼠牺牲了,所以我们开始了一个新的训练回合。但是我们可以看到,在两个探索步骤后,智能体变得更聪明了。
随着智能体继续探索和利用环境,并使用 TD 目标更新 Q 值,** Q 表中的近似值越来越好。因此,在训练结束时,我们将获得 Q 函数的最优估计。**
回顾一下
Q-learning 算法是一种强化学习算法,具有以下主要特点:
- 它会训练一个 Q 函数,这是一种动作价值函数,其内部有一个 Q 表格,用于存储所有状态-动作对的值。
- 当给定一个状态和动作时,Q 函数会在 Q 表格中查找相应的值。
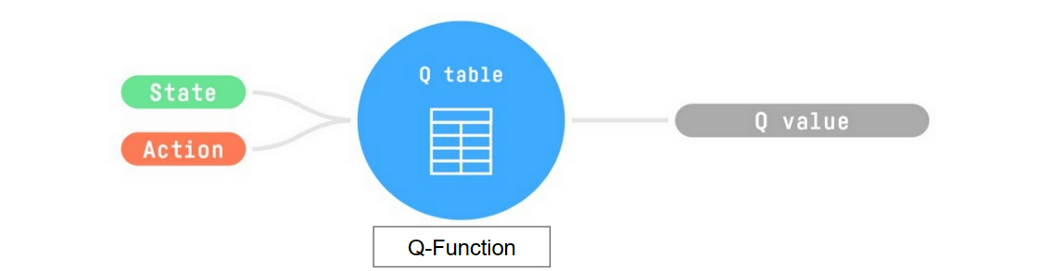
- 在训练完成后,我们会得到一个最优的Q函数,从而获得一个最优的Q表格。
- 当我们拥有一个最优的 Q 函数时,我们就能得到一个最优策略,因为我们知道在每个状态下应该采取什么最佳动作。

然而,在一开始,我们的 Q 表格是没用的,因为它为每个状态-动作对提供了任意的值(通常我们会将 Q 表初始化为全零值)。但随着我们不断地探索环境并更新Q表格,它将为我们提供越来越好的近似值。

以下是 Q-learning 算法的伪代码:
