2.6_初探Q-Learning
什么是Q-Learning?
Q-Learning是一种异策略的基于价值的方法,它使用时序差分方法来训练其动作价值函数:
- 异策略:我们将在本单元的最后讨论这个问题。
- 基于价值的方法:通过训练一个价值函数或动作价值函数来间接地找到最优策略,该函数能告诉我们每个状态或每个状态-动作对的价值。
- 使用时序差分方法:在每一步更新其动作价值函数,而不是在回合结束时进行更新。
Q-learning是我们用来训练 Q 函数的算法,Q 函数是一个动作价值函数,用于确定在特定状态下采取特定动作的价值。
让我们回顾一下价值和奖励之间的区别:
- 状态的价值或状态-动作对的价值是智能体在此状态(或状态-动作对)开始行动并按照其策略行事时预期的累积奖励。
- 奖励是在状态下执行动作后从环境中获得的反馈。
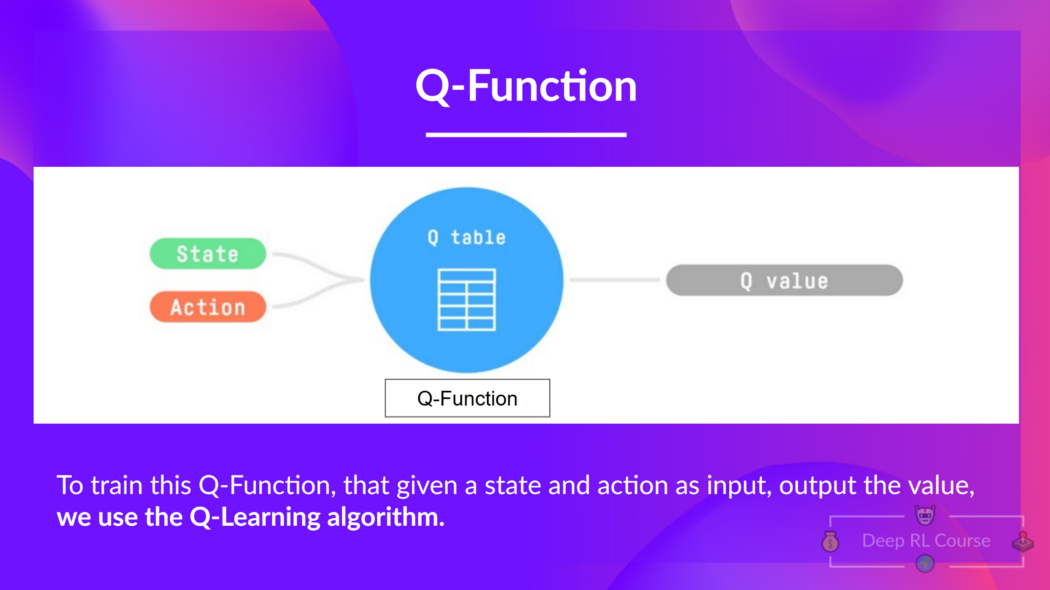
在内部,Q 函数有一个Q 表格,这个表中的每个单元格对应一个状态-动作对的价值。可以将这个 Q 表格视为 Q 函数的记忆或速查表。
让我们通过一个迷宫的例子来解释以上内容。

我们对Q表格进行初始化,所以其中的值都为0. 这个表格包含了每个状态的四个状态-动作值。
对于这个简单的例子,状态仅由鼠标的位置定义。因此,在我们的Q表中我们有2*3行,每行对应鼠标可能的每一种位置。在更复杂的情况下,状态可能包含比行动者位置更多的信息。

在这里我们可以看到,初始状态向上的状态-动作值为 0:

因此,Q 函数包含一个 Q 表格,其中包含每个状态动作对的值。给定一个状态和动作,Q 函数会在其 Q 表格中搜索并输出该值。
回顾一下,Q-learning是一个包含以下过程的强化学习算法:
- 训练一个 Q-函数(一个动作价值函数),其内部是一个包含所有状态-动作对值的Q表格。
- 给定状态和动作,我们的Q函数会在其 Q 表格中查找相应的值。
- 当训练完成后,我们有了一个最优的 Q-函数,这意味着我们有了最优的 Q 表格。
- 如果我们拥有最优的 Q 函数,我们拥有最优的策略,因为我们知道每个状态下应该采取的最佳动作。

但是,在开始时我们的Q表格是没有用的,因为它给每个状态-动作对赋予了任意的值(大多数情况下,我们把 Q 表格初始化为 0)。随着智能体探索环境并更新 Q 表格,它会给我们更好的近似最优策略。

Q-learning 算法
这是 Q-learning 的伪代码;让我们研究一下其中的每一部分,并在实现它之前**用一个简单的例子看看它是如何工作的。**不要被它的形式吓到,它比看起来简单!

第一步: 初始化 Q 表格

我们需要初始化 Q 表格中的每个状态动作值。大多数情况下,我们用 0 来初始化。
第二步: 使用 epsilon 贪心策略选择一个动作
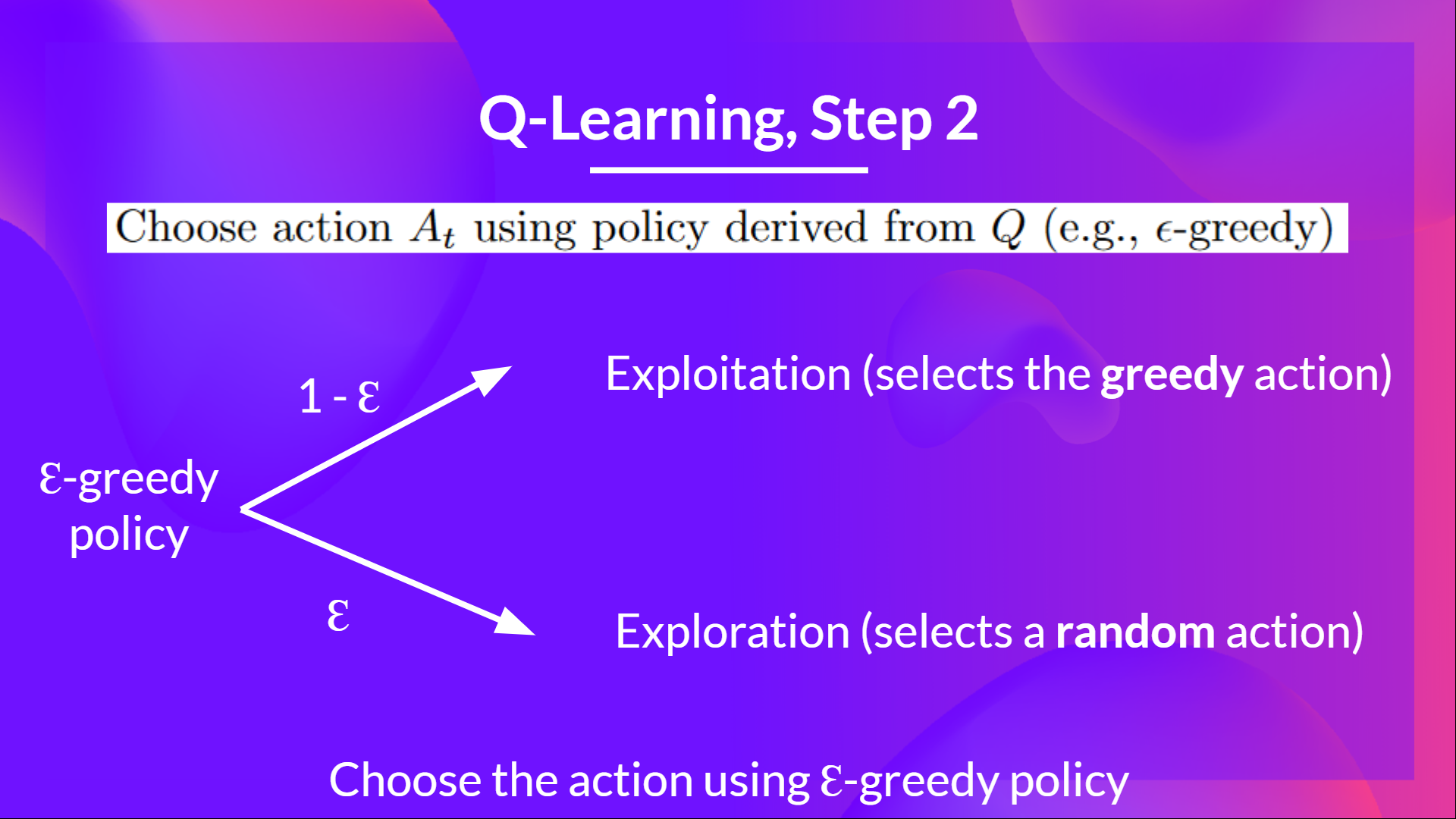
epsilon-贪心策略是一种处理探索与利用权衡的策略。
其思想是首先定义初始 epsilon ɛ = 1.0:
- 概率 1 — ɛ:智能体进行利用(即智能体选择具有最高状态-动作对值的动作)。
- 概率 ɛ:智能体进行探索(尝试随机动作)。
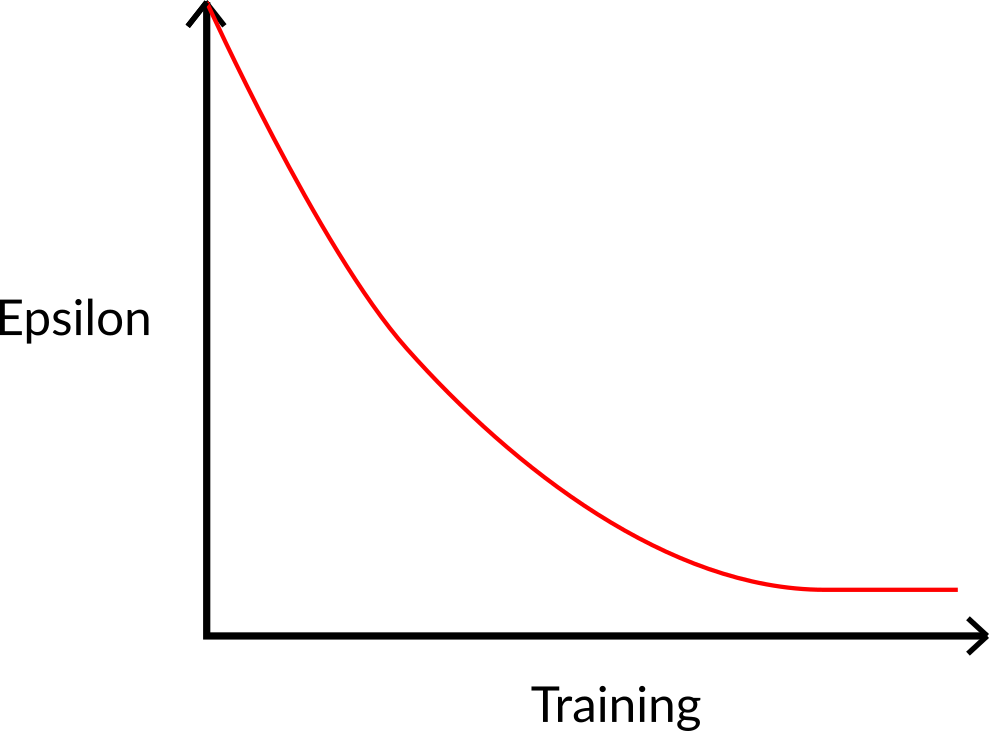
在训练开始时,由于 ɛ 值很高,进行探索的概率会很大,所以智能体大部分时间都在探索。但随着训练的进行,Q表格在估计中越来越准确,所以逐渐降低 epsilon 值,因为智能体逐渐不再需要探索,而需要更多地进行利用。
第三步: 执行动作 At, 得到奖励 Rt+1 和下一个状态 St+1

第四步: 更新 Q(St, At)
需要注意的是,在时序差分学习中,我们在与环境交互之后更新策略或价值函数(取决于我们选择的强化学习方法)。
为了计算时序差分目标(TD target),我们使用即时奖励 (R_{t+1}) 加上下一个状态最佳状态-动作对的折扣价值(称之为自举)。
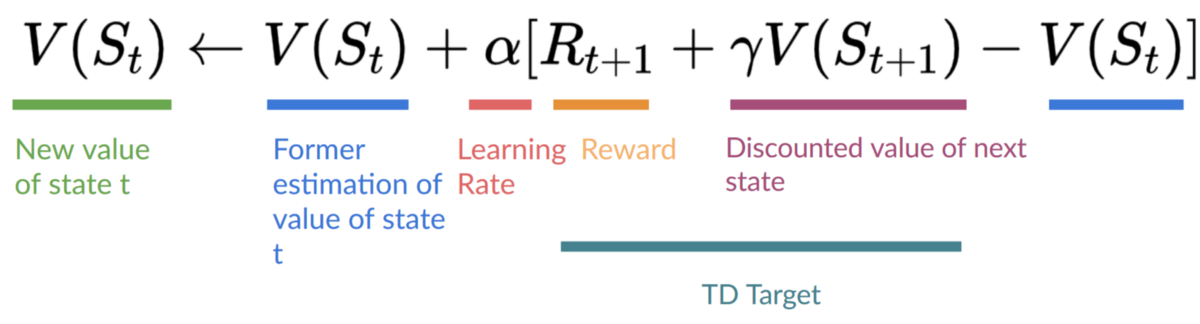
因此,(Q(S_t, A_t)) 更新公式如下:
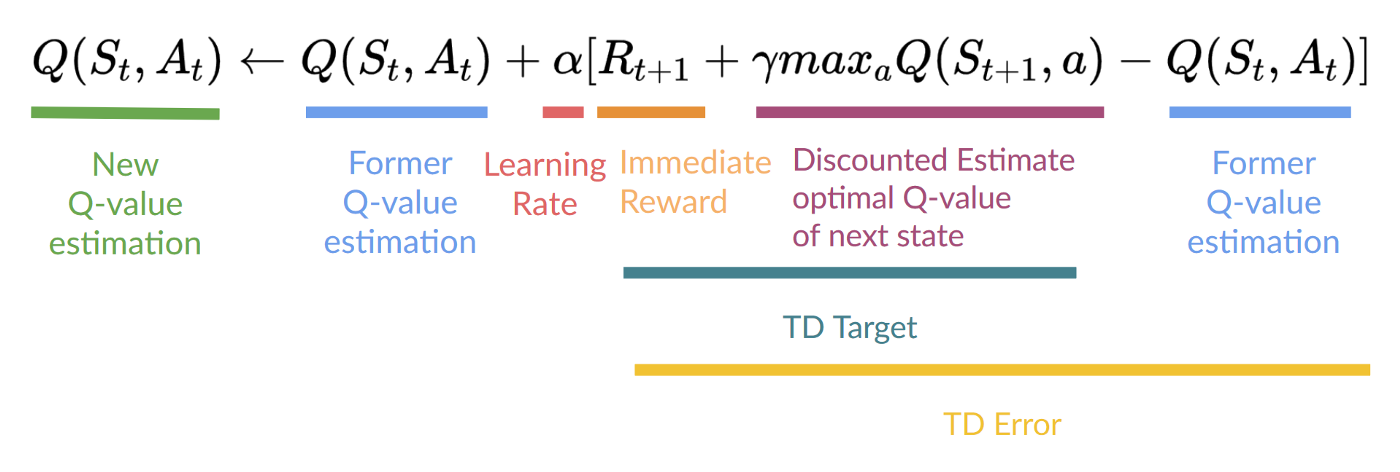
这意味着要更新 (Q(S_t, A_t)):
- 需要 (S_t, A_t, R_{t+1}, S_{t+1})。
- 需要更新给定状态-动作对的 Q 值,使用时序差分目标。
如何形成时序差分目标?
- 在采取动作 \(A_t\) 后获得奖励 \(R_{t+1}\)。
- 为了获得最佳的下一个状态-动作对值,使用贪心策略来选择下一个最佳动作。需要注意的是,这不是一个 ε-贪心策略,其将始终采取具有最高状态-动作值的动作。
然后,在此Q值更新完成后,将开始一个新的状态,并再次使用 ε-贪心策略选择动作。
这就是为什么我们说Q学习是一种异策略算法。
异策略 vs 同策略
它们之间只有细微的区别:
- 异策略:在行动(推断)和更新(训练)部分中使用不同的策略。
例如,使用 Q 学习,ε-贪心策略(行动策略),与**用于选择最佳下一状态动作值来更新Q值(更新策略)**的贪心策略不同。
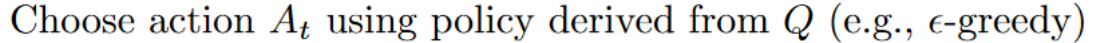
与我们在训练部分中所使用的策略不同:
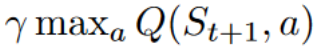
- 同策略:在行动和更新部分中使用相同的策略。
例如,在另一种基于值的算法Sarsa中,执行ε-贪心策略时,它选择的不是最优动作,而是下一个状态-动作对。

