2.5_学习进展回顾
在我们深入学习 Q-learning 算法前,先总结一下我们之前都学了什么。
我们学了两种基于价值的函数:
- 状态价值函数:如果智能体在一个给定的状态开始行动,并在之后的行动中一直遵循该策略,则输出该状态的期望回报。
- 动作价值函数:如果智能体在给定的状态开始采取一个给定的行为,并在之后的行动中一直遵循该策略,则输出该状态的期望回报。
- 在基于价值的方法中,相比于学习策略,我们手动定义策略并且学习一个价值函数。如果我们有一个最优价值函数,那就有了一个最优的策略。
还学了两种可以学习价值函数的策略的方法:
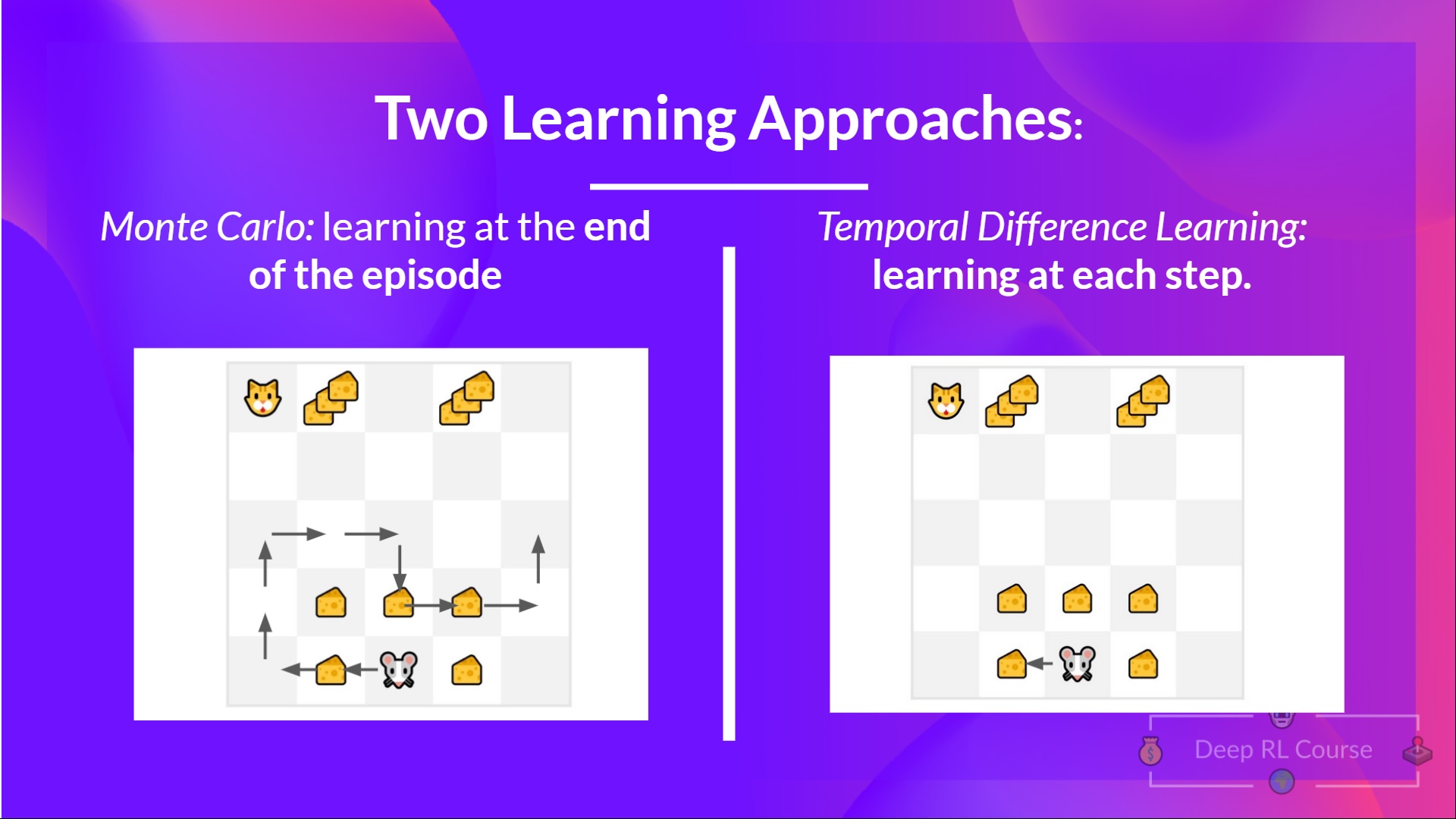
- 使用蒙特卡洛方法时,我们从完整的一轮游戏中更新值函数,并且使用该轮游戏的真实、准确的折扣回报。
- 使用TD学习方法时,我们从一个时间步中更新值函数,因此我们用一个被称为TD目标的估计回报替换我们没有的G_t。
学习进展测验
最好的学习方法是对自己进行测试。这能避免过度自信并帮助我们找到需要加强的方面。
Q1: 找到最优策略的两种主要方法是什么?
<Question
choices={[
{
text: "基于策略的方法",
explain: "使用基于策略的方法,我们直接训练策略来学习在给定状态下采取哪种行动。",
correct: true
},
{
text: "基于随机的方法",
explain: ""
},
{
text: "基于价值的方法",
explain: "使用基于价值的方法,我们训练一个价值函数来学习哪些状态更有价值,并使用该价值函数来选择最优的动作。",
correct: true
},
{
text: "进化策略方法",
explain: ""
}
]}
/>
Q2: 什么是贝尔曼方程?
答案
贝尔曼方程是一个递归方程,其工作原理如下:我们不需要从每个状态的起点开始计算回报,而是可以将任意状态的价值视为:
Rt+1 + gamma * V(St+1)
即时奖励 + 之后状态的折扣价值。
Q3: 贝尔曼方程的每个部分的定义是什么?

答案

Q4: 蒙特卡洛(Monte Carlo)方法和时序差分(Temporal Difference, 简称TD)学习方法之间的差异是什么?
<Question
choices={[
{
text: "在使用蒙特卡罗方法时,我们从一个完整的回合中更新价值函数",
explain: "",
correct: true
},
{
text: "在使用蒙特卡罗方法时,我们从一个时间步中更新价值函数",
explain: ""
},
{
text: "在使用TD方法时,我们从一个完整的回合中更新价值函数",
explain: ""
},
{
text: "在使用TD方法时,我们从一个时间步中更新价值函数",
explain: "",
correct: true
},
]}
/>
Q5: 时序差分算法中每一部分的定义是什么?

答案

Q6: 蒙特卡洛算法中每一部分的定义是什么?

答案

恭喜你完成了这个测验🥳,如果你错过了一些要点,花点时间再读一遍前面的部分,以加强你的知识(😏)。