2.2_两种基于价值的方法
在基于价值的方法中,我们将学习一个价值函数,该价值函数可以估算在某个状态下所能获得的预期回报,即它将一个状态映射到处于该状态的期望值。

一个状态的价值是智能体按照给定策略,从当前状态开始行动所能获得的预期折扣回报。
按照给定策略行动是什么意思呢?因为在基于价值的方法中没有策略,我们训练的是价值函数,而不是策略。
要记得智能体的目标是有一个最优策略π*。
为了找到最优策略,我们使用两种不同的方法进行学习:
- 基于策略的方法: 直接训练策略,以选择在给定状态下采取的动作(或者在该状态下的动作概率分布)。在这种情况下,我们没有价值函数。
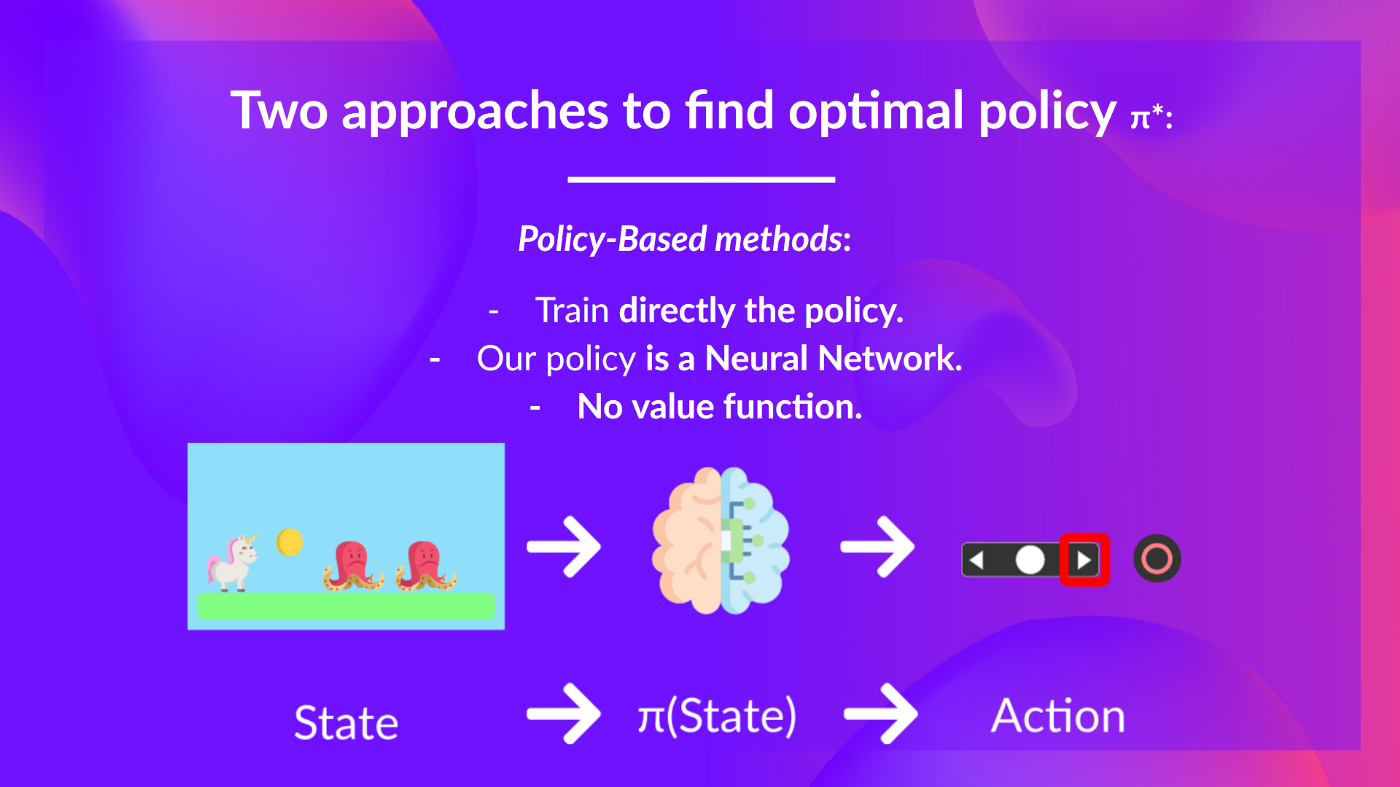
策略以状态为输入,输出在该状态下要采取的动作(确定性策略:给定状态输出一个动作的策略,与随机策略相反,随机策略输出动作的概率分布)。
因此,我们不是直接设定策略的行为;而是通过训练来设定行为。
- 基于价值的方法: 通过训练一个价值函数来间接地确定策略。这个价值函数会输出一个状态或者状态-动作对的价值。给定这个价值函数,我们的策略将采取相应的动作。
由于策略没有被训练/学习,我们需要指定它的行为。例如,如果我们想要一个策略,使得其满足:给定价值函数,它将总是采取能够带来最大奖励的动作。这意味着我们需要定义一个贪心策略。

因此,无论我们使用哪种方法来解决问题,我们都要有一个策略。在基于价值的方法中,我们不需要训练策略:策略只是一个简单的预先指定的函数(例如贪心策略),它使用价值函数给出的值来选择动作。
所以区别在于:
- 在基于策略的方法中,通过直接训练策略来找到最优策略(表示为π*)。
- 在基于价值的方法中,找到最优价值函数(表示为Q*或V*,我们稍后会讨论区别)意味着拥有了最优策略。

其实大多数时候,在基于价值的方法中,我们会使用Epsilon贪心策略来处理探索和利用之间的权衡问题;在本单元第二部分讨论Q-Learning时,我们会谈到这个问题。
所以,现在我们有两种类型的基于价值的函数:
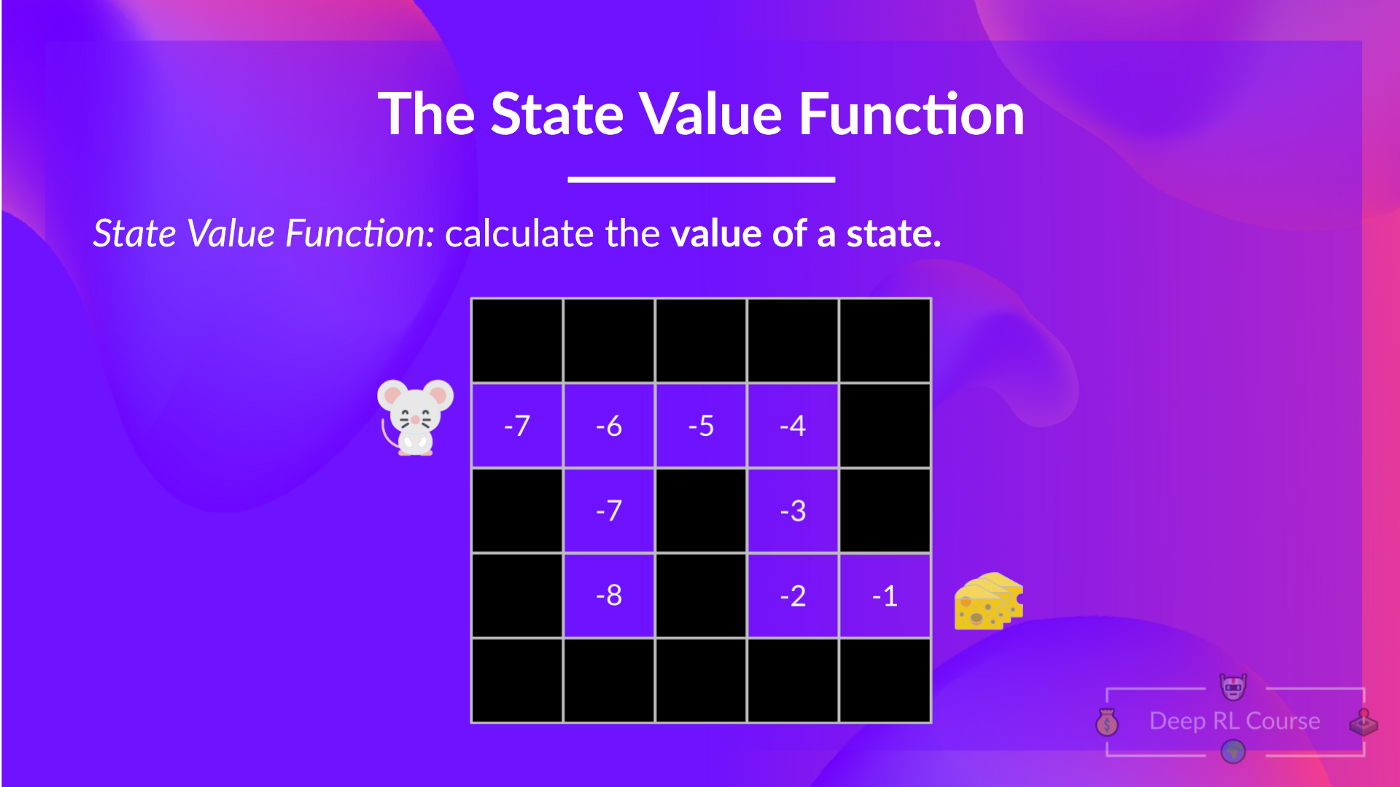
状态价值函数
策略π下的状态价值函数如下所示:
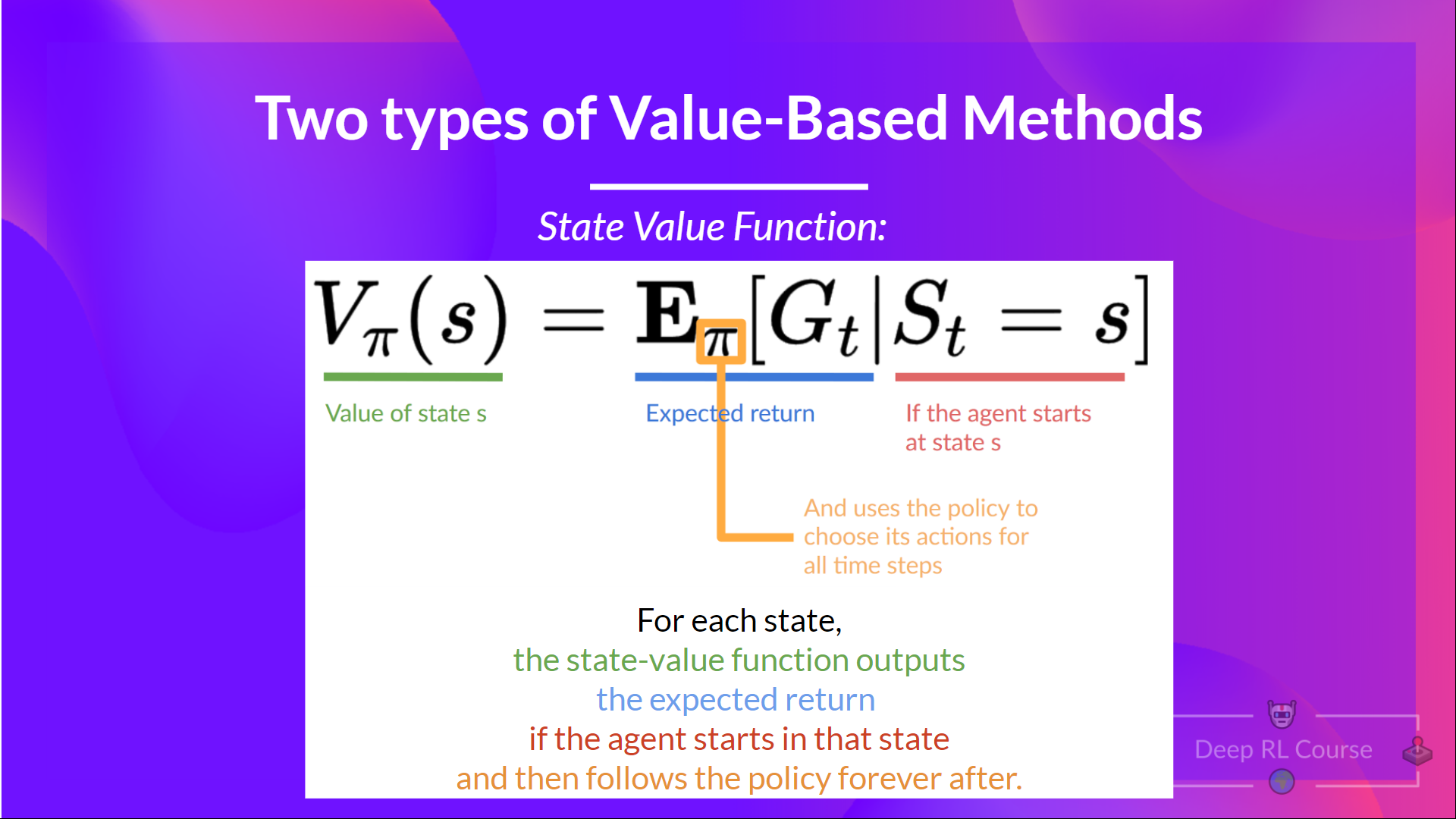
对于每个状态,状态价值函数会输出智能体按照给定策略从当前状态开始行动所能获得的预期回报(也可以理解为所有未来的时间步)。
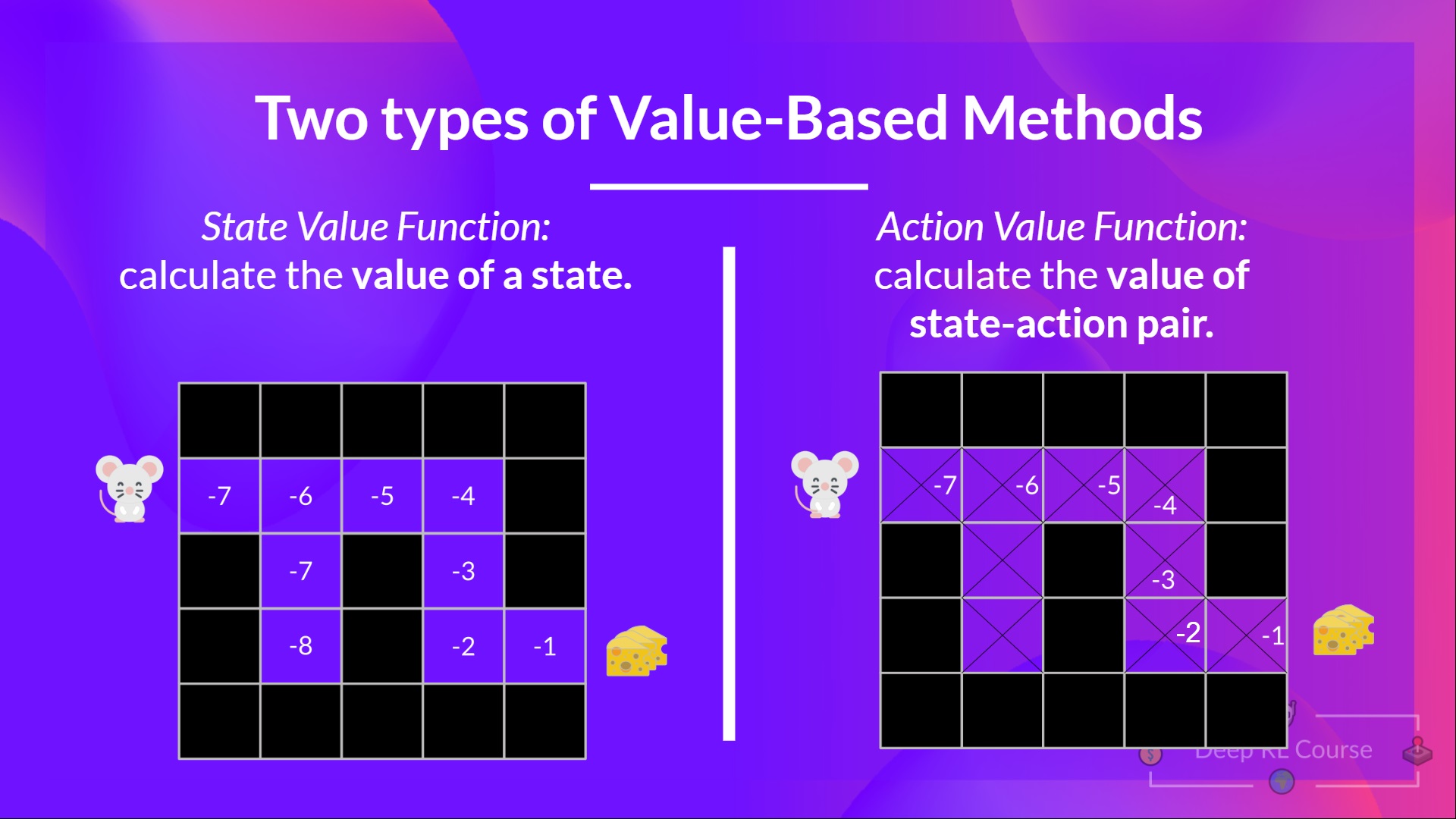
动作价值函数
在动作价值函数中,对于每个状态和动作对,动作价值函数会输出智能体按照给定策略,从当前状态开始行动所能获得的预期回报。
在策略(π)下,智能体在状态(s)中执行动作(a)的价值计算如下所示:


我们可以看到两者之间的区别是:
- 在状态价值函数中,我们计算状态 (S_t) 的价值
- 在动作价值函数中,我们计算状态-动作对((S_t, A_t))的价值,即在该状态下采取该动作的价值。
无论哪种情况,无论我们选择哪种价值函数(状态价值或动作价值函数),返回的值都是期望回报。
然而,问题是这意味着要计算每个状态或状态-动作对的价值,我们需要求智能体从该状态开始可以获得的所有奖励的总和。
该过程计算成本可能比较高,所以接下来我们将要用到贝尔曼方程。