2.1_Q-learning算法介绍

在本节课程的第一单元中,我们已经学习了强化学习、强化学习训练过程以及不同的解决强化学习的方法。我们还训练了第一个智能体并将其上传到了HuggingFace社区。
在本单元,我们将更深入的学习一种强化学习的方法:基于价值的方法,并开始学习第一个强化学习算法:Q-learning算法。
我们还会从零开始实现第一个Q-learning强化学习智能体,并在两个环境中训练它。
- Frozen-Lake-v1 (不打滑的版本): 在这里我们的智能体需要通过在冰面(F)上行走并躲避冰坑(H),使其从初始状态(S)到目标状态(G)。
- 自动出租车:在这里我们的智能体需要学习在城市中行驶从而把乘客从点A送到点B。
我们具体要学习以下内容:
- 学习基于价值的方法。
- 了解蒙特卡洛和时序差分学习之间的区别。
- 理解并实现我们的第一个强化学习算法:Q-learning。
如果你想要进一步学习 Deep Q-learning 算法,那一定要重视本单元的基础学习。Deep Q-learning 是第一个在部分 Atari 游戏上(如breakout, 太空入侵者等)表现超过人类的深度强化学习算法。
现在让我们开始吧!🚀
回顾一下
在强化学习中,我们构建一个能做智能决策的智能体。例如,一个学习玩电子游戏的智能体,或一个能够通过决定商品的购入种类和售出时间从而最大化收益的交易智能体。
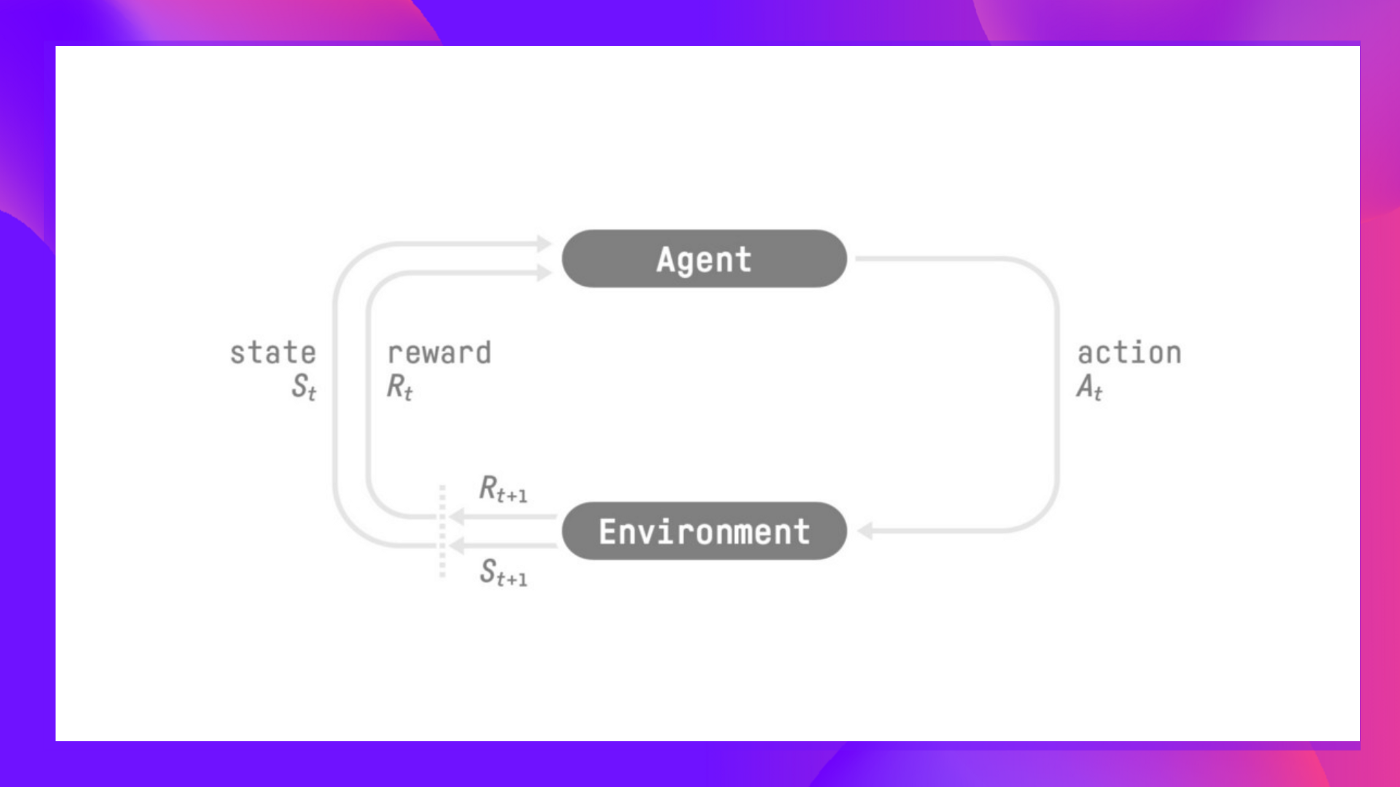
但是为了做出比较聪明的决策,我们的智能体需要从环境中学习,通过试错的方法与环境交互,并接受奖励(正向或负向)作为唯一反馈,以此进行学习。
智能体的目标是最大化累计期望奖励(基于奖励假设)
智能体的决策过程称作策略π:给定一个状态,一个策略将输出一个动作或一个动作的概率分布。也就是说,给定一个环境的观察,策略将会输出一个行动(或每一个动作的概率),智能体将会执行该动作。

我们的目标是找到一个最优的策略π*,也就是一个能够获得最好的累计期望奖励的策略。
找到这个最优策略(从而解决强化学习问题),有两种主要的强化学习方法:
- 基于策略的方法:直接训练策略,从而根据给定的状态来学习要执行的动作。
- 基于价值的方法:训练一个价值函数来学习哪个状态更有价值,并用这个价值函数采取对应的动作。

在本单元中,我们将深入学习基于价值的方法。