1.6_两种主要方法
两种解决RL问题的主要方法
换句话说,怎么构建一个 RL 智能体,让其能够挑选最大化期望累计奖励的动作
π策略:智能体的大脑
π策略是智能体的大脑,它是告诉我们在给定状态下采取什么行动的函数。因此它定义了智能体在给定时间的行为。
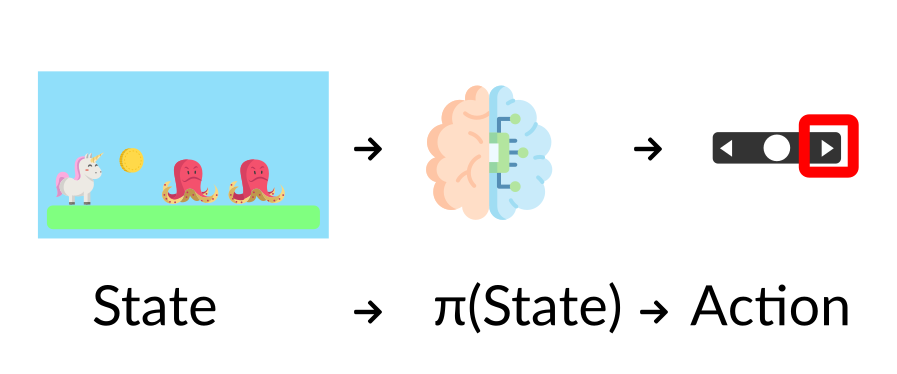
这个策略是我们想要学习的函数的,我们的目标是找到最优策略 π* ,当智能体根据这个策略行动时返回最大期望回报。我们通过训练找到 π*
这里有两种方式去训练我们的智能体找到最优策略π*:
- 直接型 ,通过教授智能体学习采取哪个动作,并给出当前状态:基于策略方法
- 间接型 ,通过教授智能体学习哪个状态更有价值,并且采取动作向更有价值的状态行进:基于价值的方法
基于策略方法
在基于策略的方法中,我们直接学习一个策略函数
这个函数会定义每个状态和其最佳对应动作之间的映射。我们也可以说它定义了在那个状态下可能动作集合的概率分布。
我们有两类策略:
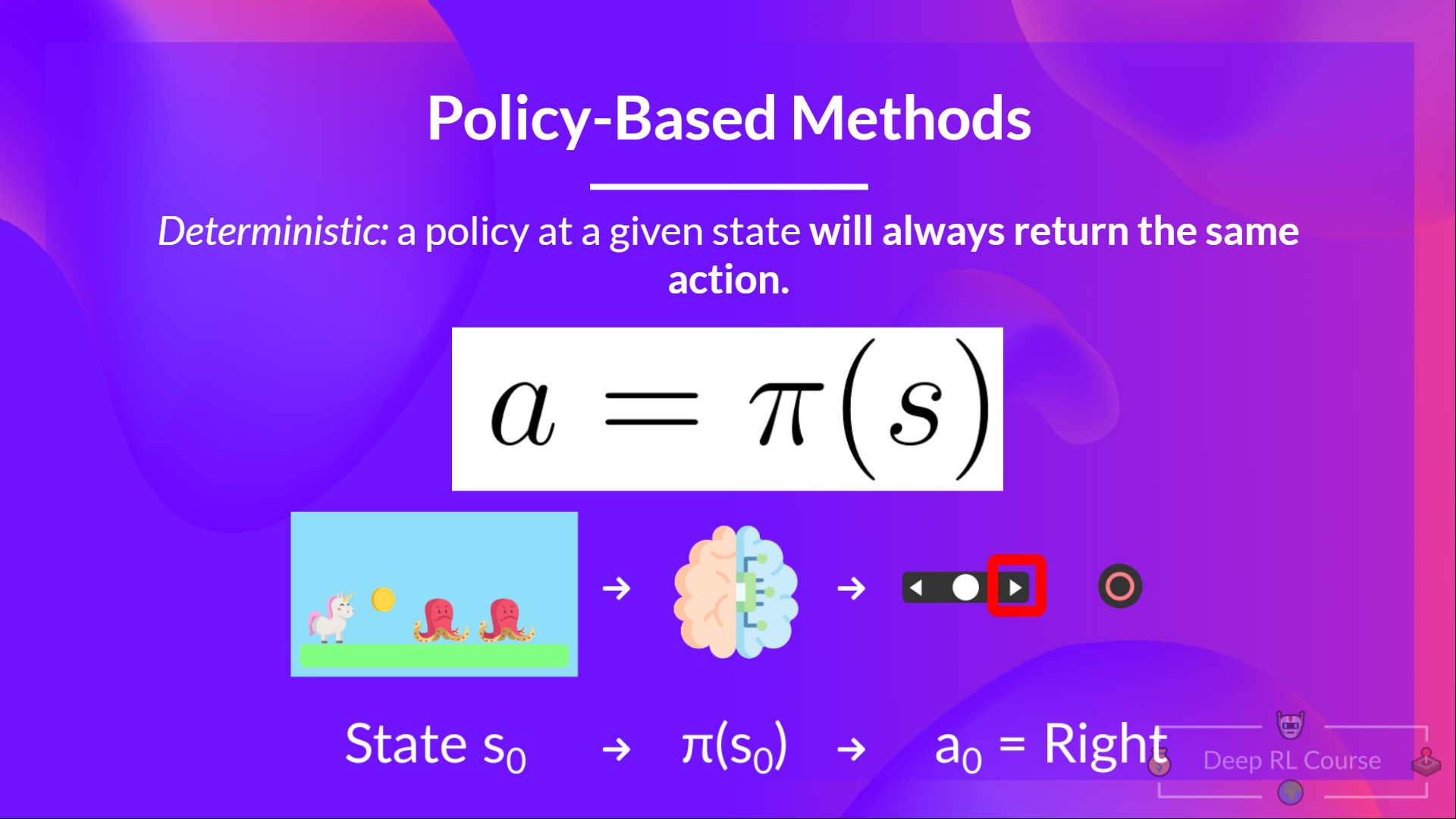
- 确定型:给定一个状态,策略返回同样的动作
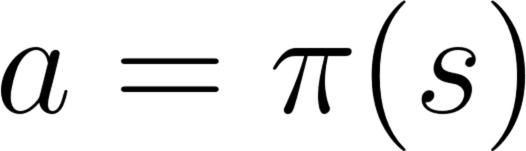
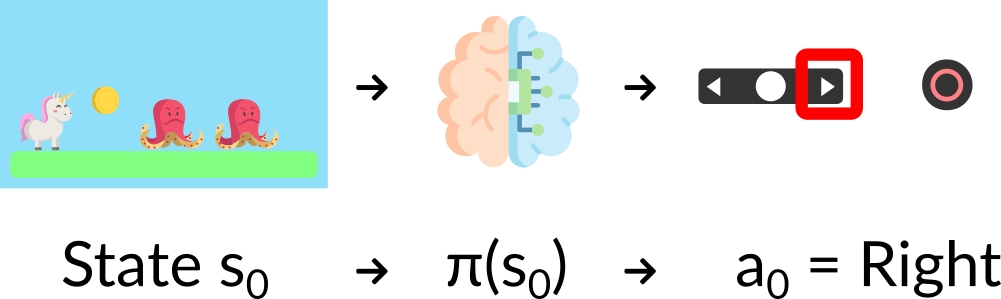
- 随机型:结果是一个动作的概率分布


回顾一下:

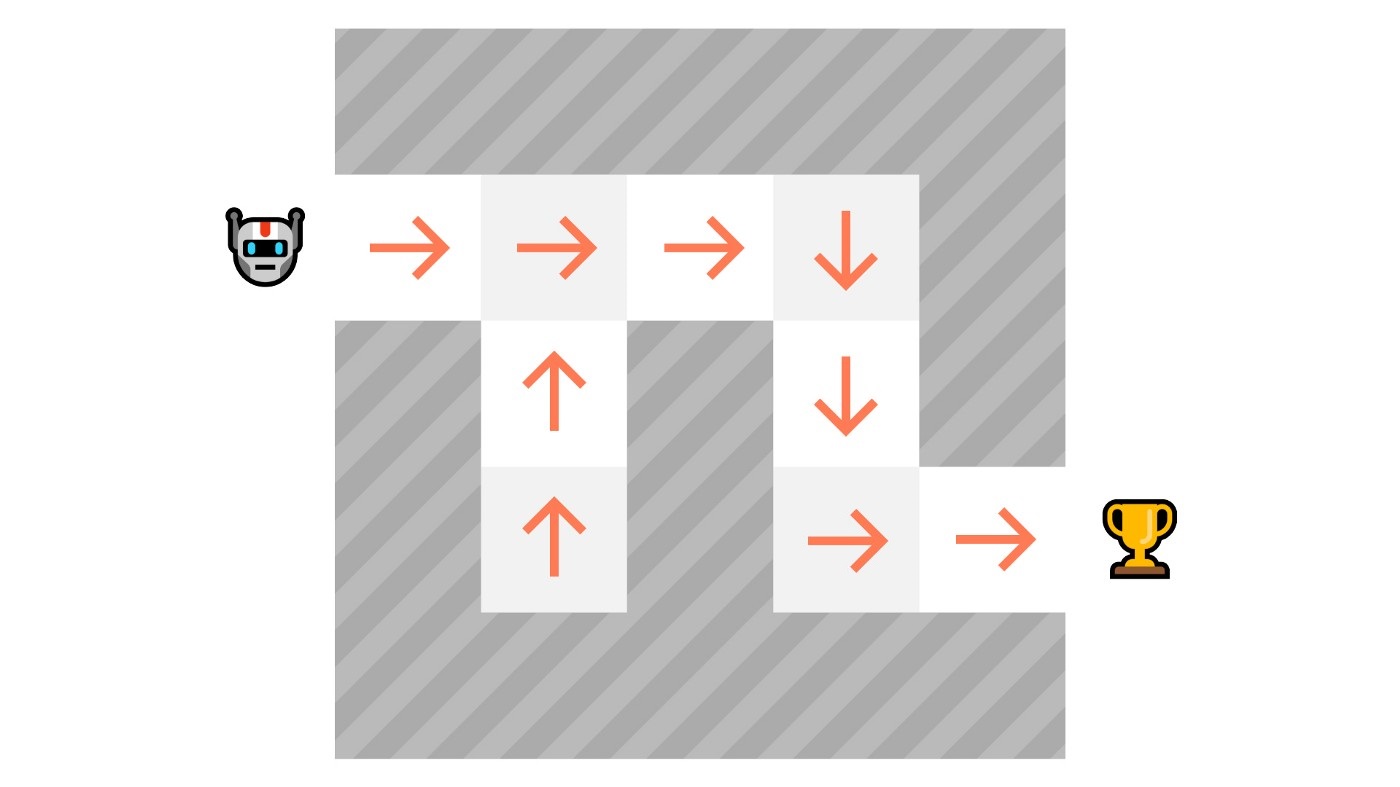
基于价值的方法
在基于价值的方法中,相比于训练一个策略函数,我们学习一个价值函数,其能将一个状态映射到该状态的期望价值。
状态的价值是智能体在该状态开始,并根据策略行动所能得到的期望折扣回报。
根据策略执行仅仅代表我们的策略是在那个状态是高价值的
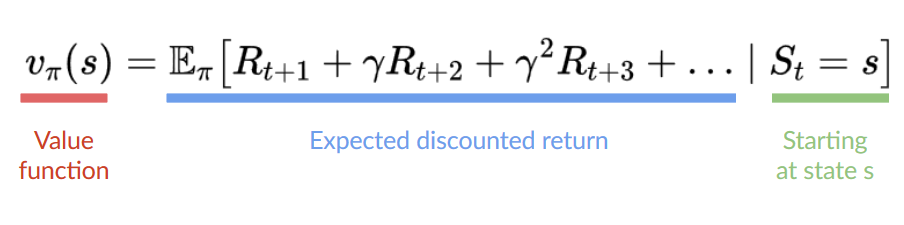
这里我们看的我们的价值函数定义了每个可能状态的价值

多亏了我们的价值函数,在每一步,我们的策略都会选择价值函数定义的最大价值的状态:-7 ,然后是 -6 ,然后是 -5 (以此类推)来达到目标。
回顾一下:

