1.5_探索利用权衡
探索/利用权衡
最后,在研究解决强化学习问题的不同方法之前,我们必须讨论一个更重要的主题:探索/利用
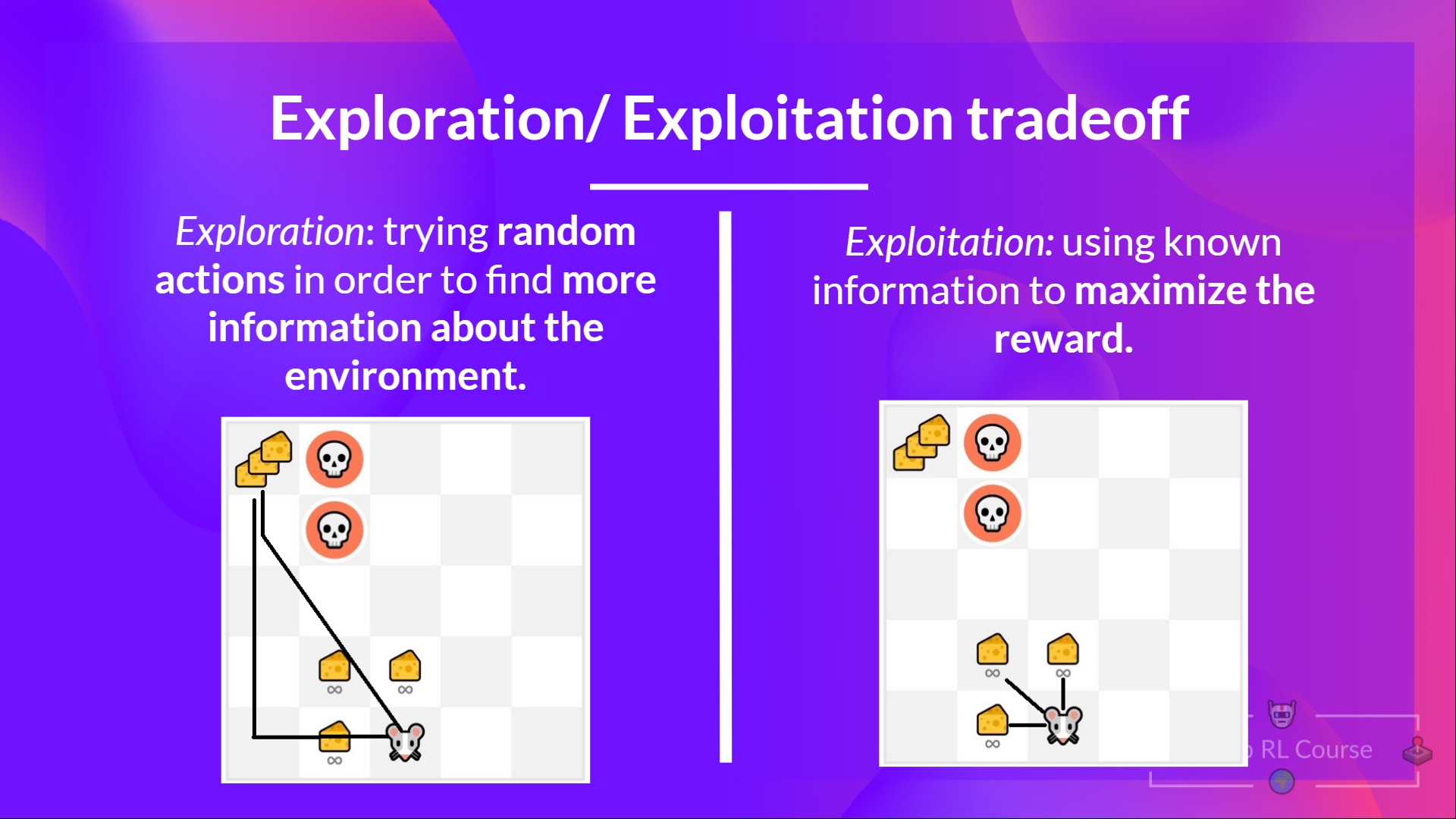
- 探索 正在通过尝试随机动作来探索环境,以找到有关环境的更多信息。
- 利用 是利用已知信息来最大化奖励。
请记住,我们的 RL 智能体的目标是最大化期望累积奖励。然而,我们可能会陷入一个常见的陷阱。
让我们举个例子:
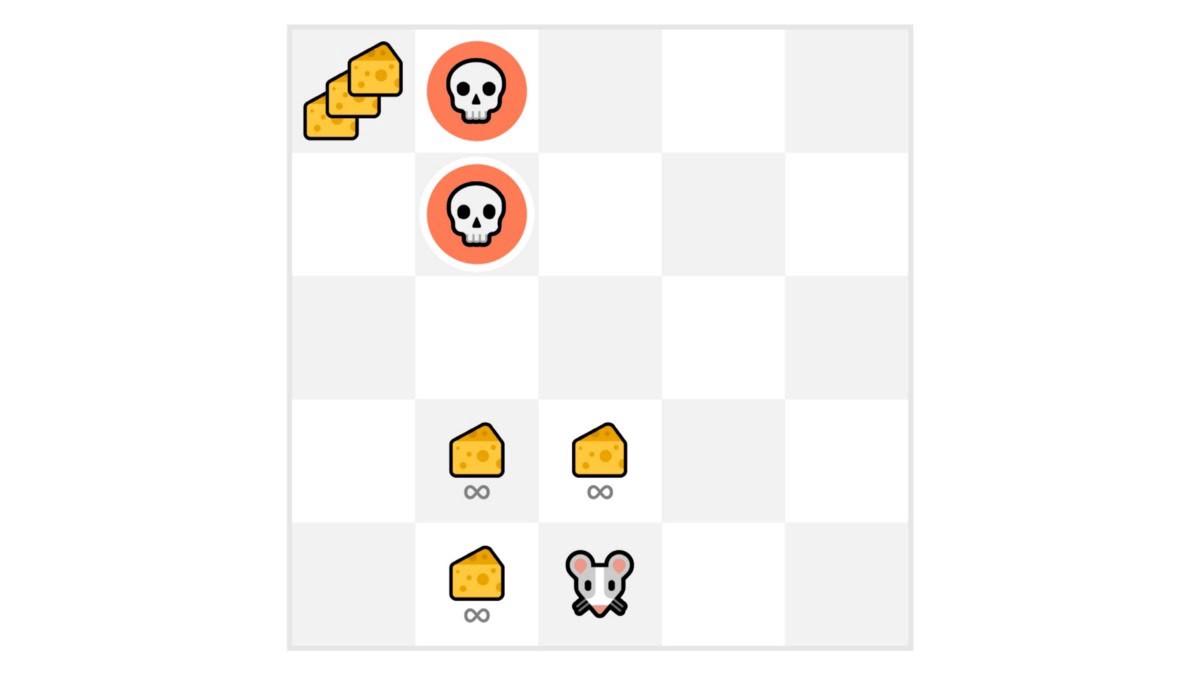
在这个游戏中,我们的老鼠可以拥有无限数量的小奶酪(每个 +1)。但是在迷宫的顶端,有一大笔奶酪(+1000)。
然而,如果我们只专注于利用,我们的智能体将永远无法取得巨量奶酪。相反,它只会利用最近的奖励来源,即使这个来源很小(利用)。
但如果我们的智能体进行一点点探索,它就可以发现大奖励(那堆大奶酪)。
这就是我们所说的探索/利用权衡。我们需要平衡探索环境的程度和利用我们对环境的了解的程度。
因此,我们必须定义一个有助于处理这种权衡的规则。我们将在以后的单元中看到处理它的不同方法。
如果还是一头雾水,想想一个真正的问题:挑选餐厅:
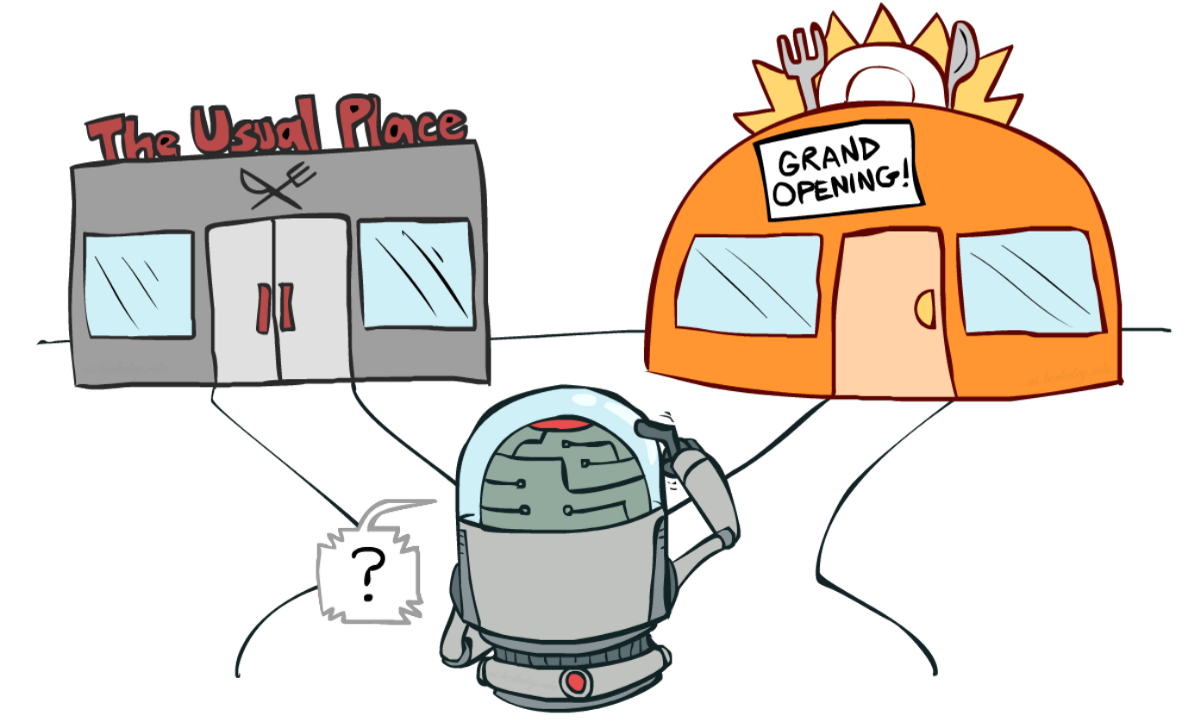
- 利用:你每天都去同一家你认为不错的餐厅,冒着错过另一家更好的餐厅的风险。
- 探索:尝试你以前从未去过的餐厅,有可能会有糟糕的体验但可能有机会获得美妙的体验。
回顾一下: