1.3_强化学习框架
RL 过程
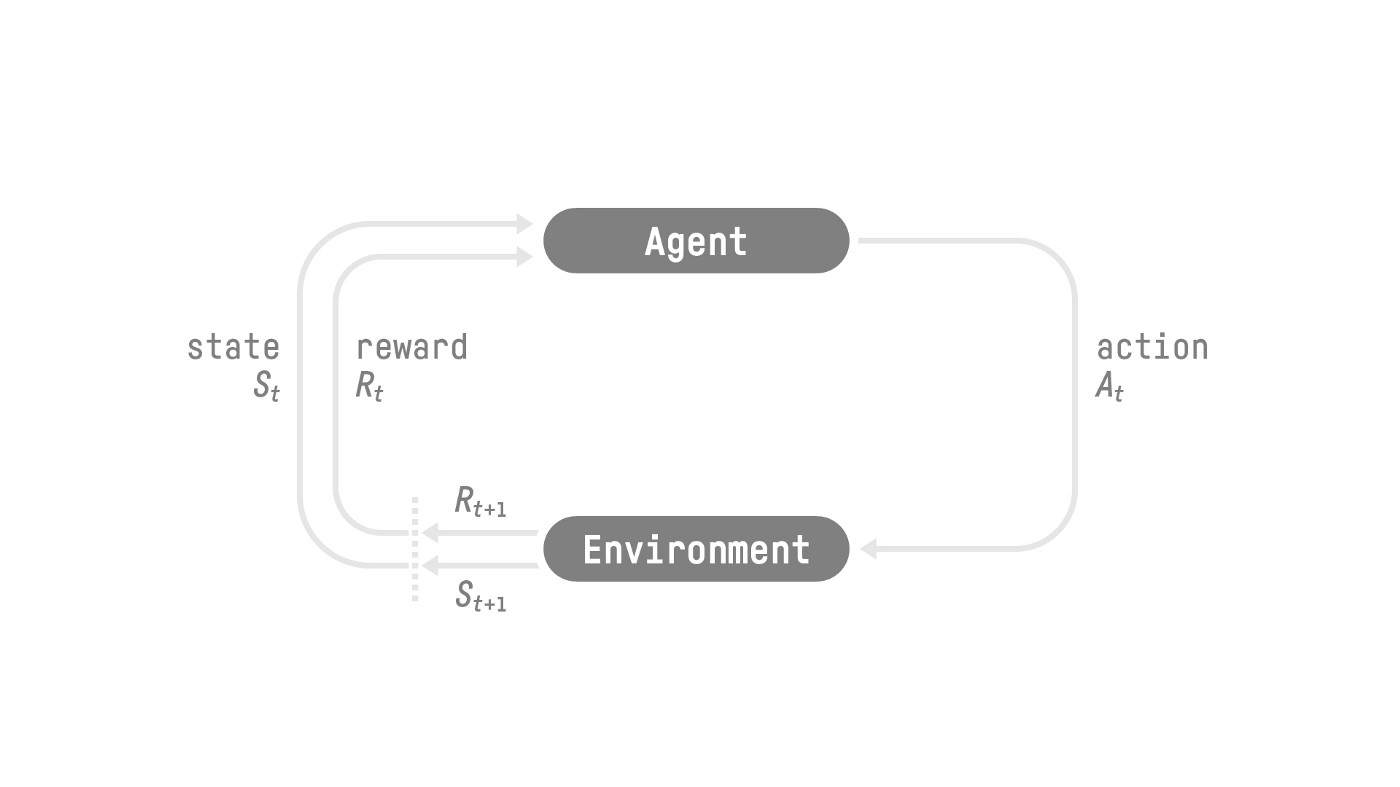
为了理解 RL 过程,让我们想象一个智能体在玩平台游戏:
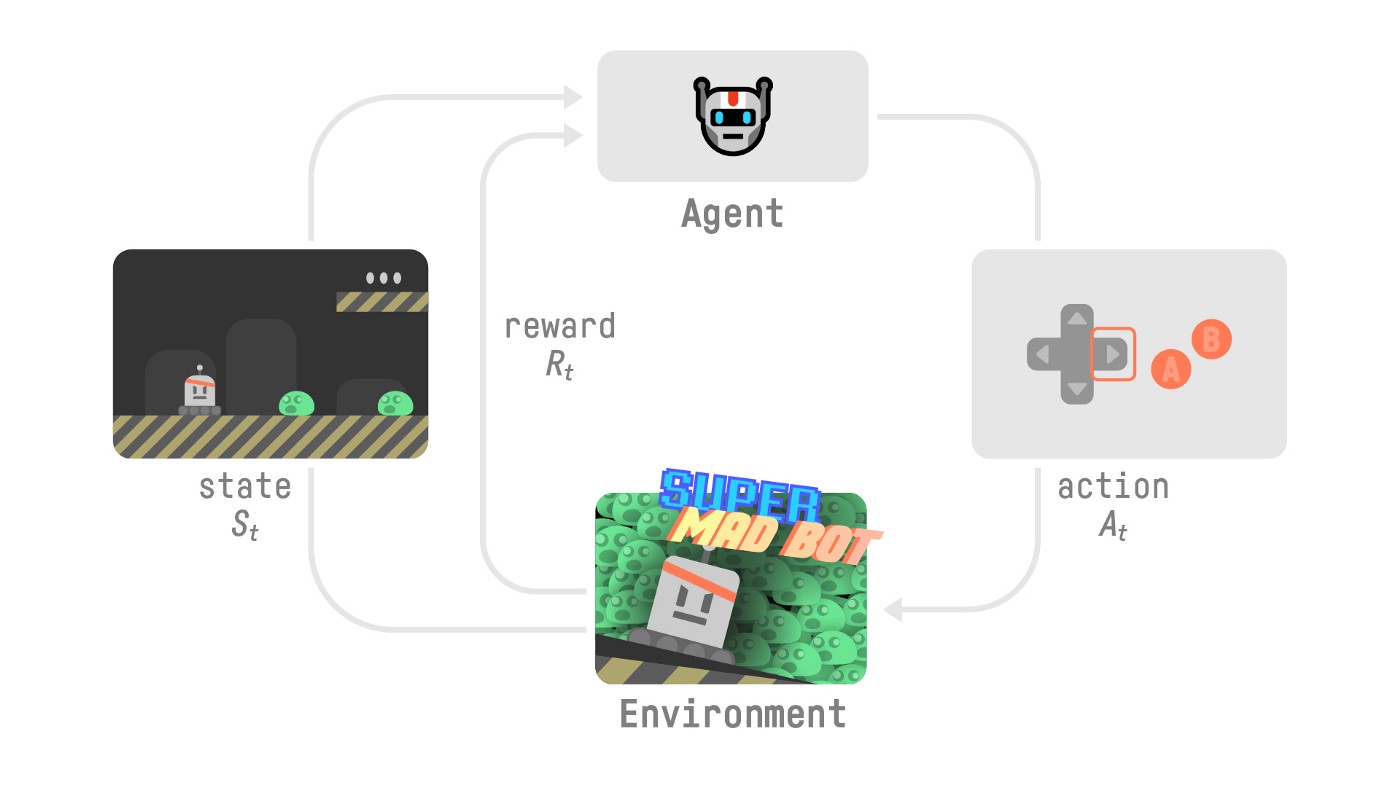
- 我们的智能体从环境接收到状态\(S_0\)——我们收到游戏的第一帧(环境)。
- 基于状态\(S_0\),智能体采取动作\(A_0\)——我们的智能体将向右移动。
- 环境进入 新 状态 \(S_1\) - 新的一帧。
- 环境给智能体一些奖励 \(R_1\) - 我们没有死*(正奖励 +1)*。
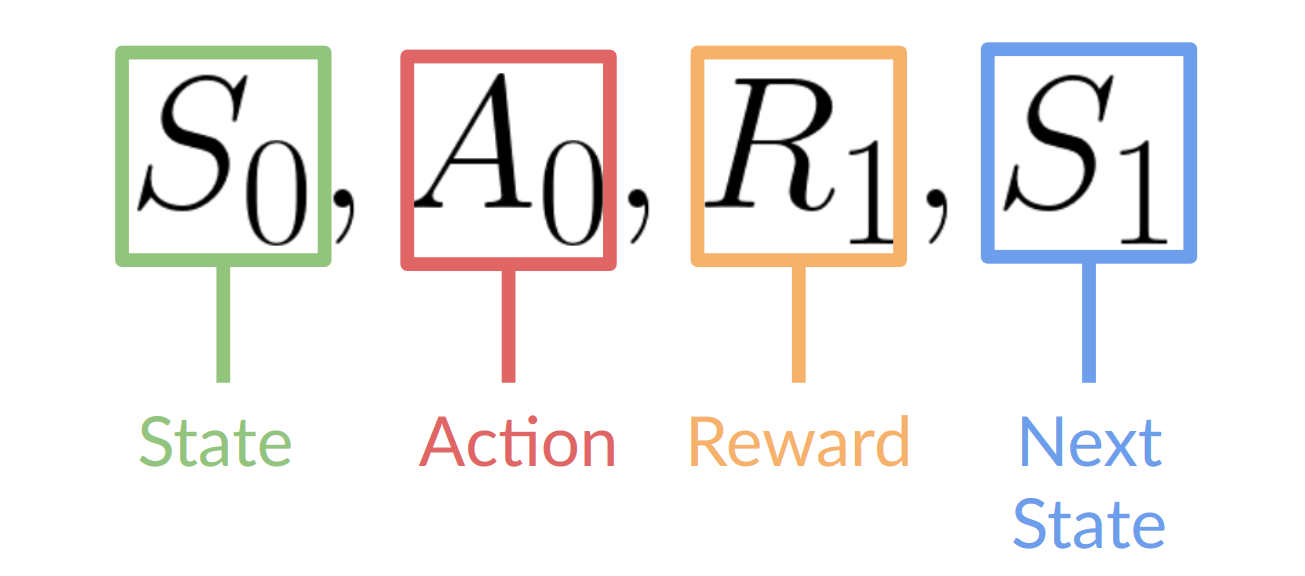
此 RL 循环输出一系列状态、动作、奖励和下一个状态。
智能体的目标是_最大化_其累积奖励,称为期望回报。
奖励假设:强化学习的核心思想
⇒ 为什么智能体的目标是最大化期望回报?
因为 RL 是基于奖励假设,即所有目标都可以描述为期望回报(期望累积奖励)的最大化。
这就是为什么在强化学习中,为了获得最佳行为,我们的目标是学习采取动作以最大化期望累积奖励。
马尔可夫性质
在论文中,你会看到 RL 过程称为马尔可夫决策过程 (Markov Decision Process,MDP)。
我们将在以下单元中再次讨论马尔可夫性质。但是如果你今天需要记住一些关于它的事情,那就是:马尔可夫性质意味着我们的智能体需要只根据当前状态来决定采取什么动作,而不是根据所有状态和动作的历史采取动作。
观测/状态空间
观测/状态是我们的智能体从环境中获取的**信息。**在视频游戏的情况下,它可以是一帧(屏幕截图)。在交易智能体的情况下,它可以是某只股票的价值等。
观测 和 状态 之间是有区别的,但是:
- 状态s:是对世界状态的完整描述(没有隐藏信息)。在完全可观测的环境中。

在国际象棋游戏中,我们可以访问整个棋盘信息,因此我们从环境中接收到一个状态。换句话说,环境被完全观测到。
- 观测 o:是对状态的**部分描述。**在部分可观测的环境中。

在《超级马里奥》中,我们只能看到靠近玩家的部分关卡,因此我们接收的是一个观测。
在《超级马里奥》中,我们处于一个部分可观测的环境中。因为我们只看到了关卡的一部分所以我们只收到一个观测。
回顾一下:

动作空间" tabindex="-1">动作空间 动作空间
动作空间是环境中所有可能动作的集合。
动作可以来自离散或连续空间:
- 离散空间:可能动作数量是有限的。
同样,在《超级马里奥》中,我们只有 4 种可能的动作:左,右,上(跳跃),下(蹲着)
在《超级马里奥》中,我们只有一组有限的动作,因为我们只有 4 个方向。
- 连续空间:可能的动作数量是无限。

回顾一下:

考虑这些信息至关重要,因为它在将来选择 RL 算法时非常重要。
奖励和折扣
奖励是 RL 的基础,因为它是智能体的唯一反馈。多亏了它,我们的智能体才知道所采取的动作是否正确。
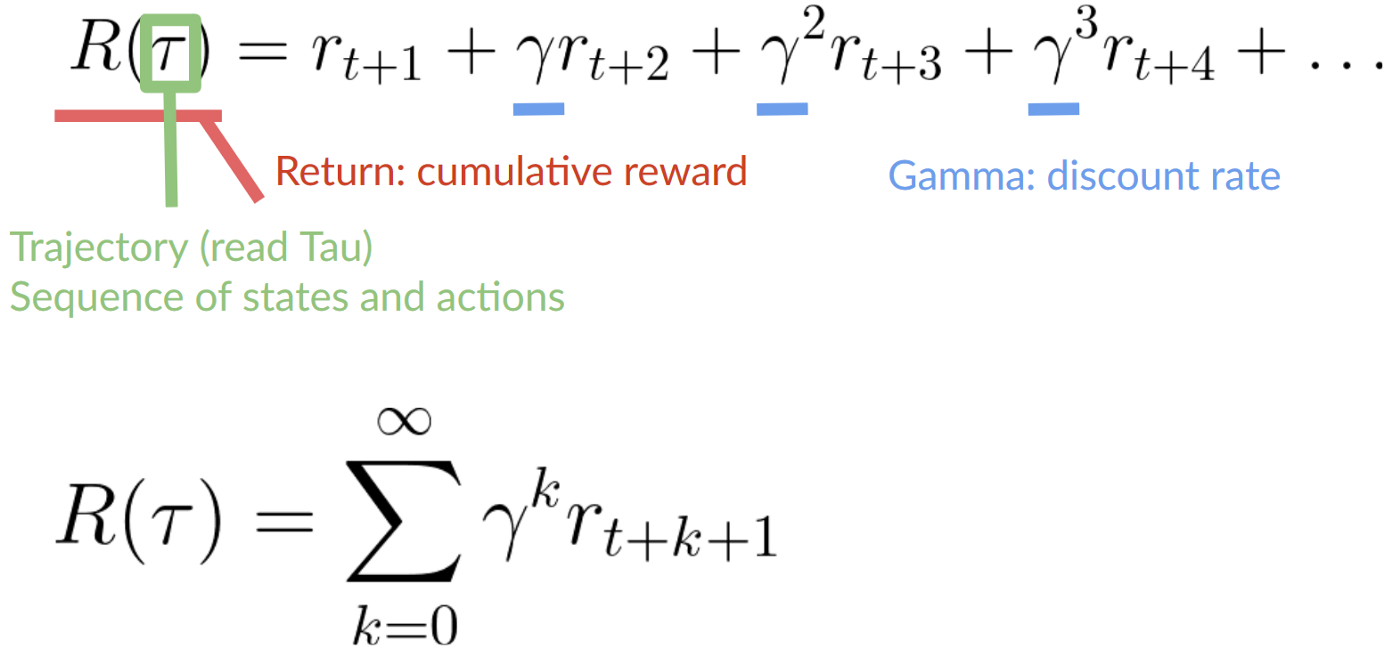
每个时间步的累积奖励 t 可以写成:
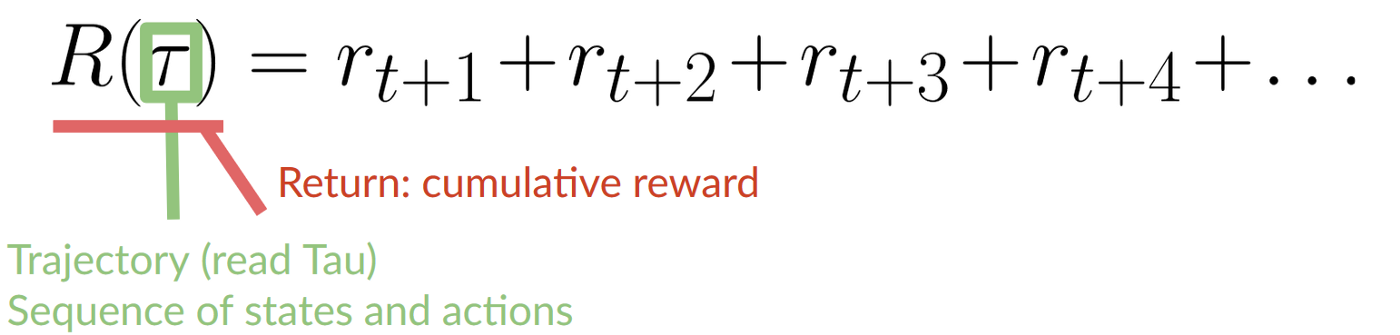
这相当于:
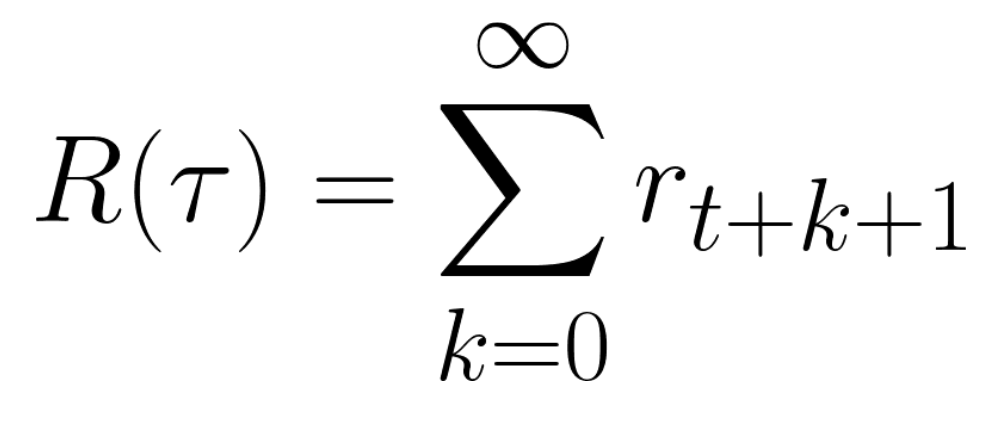
然而,在现实中,**我们不能就这样累加。**因为较早出现的奖励(在游戏开始时)更有可能发生,所以它们比长期的未来奖励更可预测。
假设你的智能体是这只小老鼠,每一步可以移动一个方块,而你的对手是猫(它也可以移动)。老鼠的目标是在被猫吃掉之前吃掉最多的奶酪。

正如我们在图中看到的,吃掉我们附近的奶酪的可能性比吃靠近猫的奶酪的可能性更大(我们离猫越近,它就越危险)。
因此,即使猫附近的奖励更大(更多奶酪),折扣也会更多,因为我们不确定是否能够吃掉它。
为了折扣奖励,我们这样做:
- 我们定义一个称为 γ 的折扣率,其必须介于 0 和 1 之间。 大多数情况下介于 0.95 和 0.99 之间。
- γ 越大,折扣越小。这意味着我们的智能体更关心长期奖励。
- 另一方面, γ 越小,折扣越大。这意味着我们的 智能体 更关心短期奖励(最近的奶酪)。
- 然后,每个奖励将通过 γ 时间步数的指数来打折扣。随着时间步数的增加,猫离我们越来越近,因此未来奖励发生的可能性越来越小。
我们的折扣期望累积奖励是: